
Actually secure boot on Fedora 39
Created: 07.10.2023 20:48 UTC
If you've set up actually secure boot as previously described on this blog on your Fedora installation, you need to make some changes when updating to Fedora 39. Luckily, updating to Fedora 39 won't break your system - it just means the kernel won't be updated anymore. However, this would turn into a problem as soon as dnf removes the modules for the kernel you are using.
As Fedora 39 and systemd-boot worked towards using UKI, some things got changed. In particular, the order of install scripts is different now, and 100-combine-and-sign.install was run too early (it should have been 99). On top of that, objcopy can no longer be used to create an .efi file with the systemd-boot stub and ukify needs to be used instead.
In order to make updating kernels work again, do the following:
sudo rm /etc/kernel/install.d/100-combine-and-sign.install
curl https://blog.nil.im/files/99-combine-and-sign.install | sudo tee /etc/kernel/install.d/99-combine-and-sign.install
# Review the code that was downloaded and printed at the same time by tee.
sudo chmod +x /etc/kernel/install.d/99-combine-and-sign.install
sudo dnf install systemd-ukify
sudo dnf reinstall kernel-core
If you reboot now and execute uname -r, it should contain .fc39 instead of .fc38. If rebooting does not work, boot the linux-old.efi, make a backup of it (e.g. linux-working.efi) and contact me.
ObjFW 1.0.1, 1.0.2 and 1.0.3 released
Created: 15.09.2023 23:36 UTC
ObjFW 1.0.1, 1.0.2 and 1.0.3 have been released. You can find further information here.
In general, I plan on having more regular releases now, which means I will only write about major releases here from now on. In order to get updates on every release, please subscribe to the ObjFW account on the Fediverse / ActivityPub (sometimes also called Mastodon, even though this instance isn't Mastodon), which is also available as an Atom feed.
ObjFW 1.0 has been released!
Created: 29.08.2023 17:36 UTC
Finally! Almost 6 years after the last unstable, I released ObjFW 1.0 today. This means the API and ABI are finally stable and overall everything should be in a good shape.
I screwed up the ObjFW Git repository
Created: 18.06.2022 19:44 UTC
Today, I realized that I screwed up the ObjFW Git repository, while the Fossil repository was fine at all times. You need to delete your clone and do a fresh clone if you checked out ObjFW via Git. Other repositories are not affected and only the master branch is affected - more on that later.
So what happened? In December 2021, shortly after Christmas and before New Years, my server died. The remote console reported a power supply failure, nothing that could be fixed remotely. And unfortunately, because it was between the years, it was impossible to get to the data center and fix the server (I would have had a spare PSU - but I was also in a different country). So I decided to set up the services that were on said server on my RockPro64, which at the time was already hosting my Matrix server. And this is where the mistake happened.
At this point, I need to go back a step and explain how the mirroring of the Fossil repository to Git works. On my server, there's a cronjob every 5 minutes that checks all Fossil repositories and exports all new commits to Git and pushes them to GitHub. Because Fossil deals with user names and Git with real names + e-mail addresses, some mapping is needed. Because Fossil's fossil git export command lacks support for such a mapping (see my previous blog post on this), I patched this mapping into the code itself. I build Fossil using pkgsrc, which makes it easy to maintain a local patch set. When I recreated this patch set on the RockPro64, I was in a huge hurry to restore all my services and made a typo: I typoed my last name in the mapping. My laptop's keyboard is sometimes bad at debouncing keys, so sometimes letters repeat, and this is exactly what happened. And given the hurry I was in, I didn't notice.
So what happened? Well, computers being computers, they do what they are told. So for half a year, it would happily push with the wrong name. And I wouldn't notice for half a year, because GitHub had the brilliant idea to fake that repositories only have a GitHub user name and not a real name + e-mail. Yes, they go through quite some length in their UI to act like Git uses GitHub user names and not real name + e-mail and make sure you never ever see a real name for a commit anywhere - you need to git clone to see that. Which in this case made sure that I would never see the typo, since I don't check ObjFW out via Git myself but only via Fossil. This is yet another case where GitHub's stupid idea to lie about commit authors caused harm (not to mention people leaking their real name when they don't want to and not noticing because GitHub acts like it's not there).
And because fixing this typo of course results in different Git commits being created, exporting from Fossil to Git after the fix rewrote all Git history since January 2022. The Fossil history of course remains unchanged and isn't being rewritten. Sorry for any inconvenience this causes.
So, why are other projects not affected, and only the master branch on ObjFW? Simple: Because I didn't even set up the mirror for anything but ObjFW's master branch when I was in the rush to restore my server and hence access to my digital life.
Blog software rewritten
Created: 02.01.2022 13:29 UTC
A few weeks ago, my server died, as some of you might have noticed. My old server was a SPARC64 machine running OpenBSD and the blog still existed as an old static binary. ObjFW's code changed plenty in the time, so it needed some updating in any case. But the new machine is no longer running OpenBSD, which added an additional problem: OpenBSD has a daemon in base called slowcgi, which can be used to make regular CGI applications speak FastCGI. The blog was still using CGI and nginx has no native support for that.
The natural solution would have been to just switch from slowcgi to something like fcgiwrap. But given the amount of setup that would be required, I opted for something else instead: Rerwite the blog to use OFHTTPServer. This was surprisingly easy to port and basically worked on the first try.
The new code can be found at the same place, with one difference: There's only one binary now and atom support is served by the same binary. You only need the Blog.mMakefiletemplates, that's all.
Edit: The code is now in a repository.
Linux on the ASUS ROG Zephyrus G14 2021
Created: 05.09.2021 12:28 UTC
A few months ago, I got an ASUS ROG Zephyrus G14, 2021 version. I got it with the 5900HS, 32 GB RAM, RTX 3060, 1440p 120 Hz display and 1 TB of SSD. I never would have imagined that I would buy a gaming notebook, but AMD's current notebook offerings convinced me and this was the best machine in 14" that I could find (the Razer Blade 14 has been released since, but that's limited to 16 GB of soldered RAM). It doesn't feel like a gaming notebook, but rather an ultrabook with insane performance. Unfortunately, my vendor got a bad batch with display issues and sent me a replacement from the same batch several times, so the problem never went away, but that's a different story.
Today, I will talk about how to run Linux on the ASUS ROG Zephyrus G14 2021 and
do most things the Armoury Crate software does on Windows without any extra
software, as I have been asked to do so by a few people. There is also a
project called "ASUS Linux" which has a guide for Fedora, which many people
recommend, but I can only strongly recommend to not follow it: It
severely weakens system security for absolutely no other reason than being lazy
and I actually got banned from their Discord for raising these issues. There is
a complete lack of understanding of concepts such as priviledge separation and
priviledge drop and instead there's a daemon running as root. The author deems
this absolutely secure because the daemon is written in Rust (history shows
this to be a common misconception by those who have no clue about security -
just because something is written in Rust doesn't make it 100% secure, it only
eliminates a single class of security vulnerabilities) - while it links in
various graphics libraries with a bad security track record to handle
displaying images on the AniMe Matrix of the G14. So essentially, this is just
one exploit in libpng or similar away from a full kernel compromize, because
they also make you disable Secure Boot. And finally, they even tell people to
install a custom kernel from Copr that has very
questionable patches:
E.g. adding udelay to avoid a race condition. For those who don't
know what that means: That is a very ugly workaround that you should never ever
do in production and leaves the underlying issue entirely unfixed.
But not everything coming from the ASUS Linux project is bad: The author actually did write some very useful patches and upstreamed them, so credit where credit is due. And it is also thanks to those patches that I can write this guide that works with a stock kernel. This just shows that upstream works: The good patches go upstream, while the bad ones don't. That's exactly how it should be.
First things first: You should use a distribution that has a modern kernel. For the G14 2021, that means 5.12 is the absolute bare minimum. I'd recommend 5.14 or, once released, 5.15, which should make standby more reliable. I'm personally using Fedora, but everything listed here should work with any distribution running a modern kernel and systemd.
The big elephant in the room for most people is probably the dGPU. By default,
when no driver is loaded, it does not idle and sucks the battery empty in less
than 2 hours. I've been told installing the NVIDIA driver fixes this, but
personally, I do not use the dGPU on Linux other than for dGPU pass-through to
a VM. So I will not install the NVIDIA driver, given that this only adds a lot
of pain for no reason. If you do install the NVIDIA driver, that still does not
require you to disabe Secure Boot - don't! Follow something like my last blog
post instead on how you can set up your own Secure Boot keys and then you can
just sign the NVIDIA kernel module with that. You also don't need the NVIDIA
driver to pass the dGPU to a VM, in fact it's easier to do without the NVIDIA
driver. But we would still like to have more than 2h of battery life, so
there's an easy solution: Simply remove the NVIDIA card from the PCIe bus. You
can automatically do this on every boot by creating a file
/etc/tmpfiles.d/asus_gpu.conf and writing the following into it:
w /sys/bus/pci/devices/0000:01:00.0/remove - - - - 1
w /sys/bus/pci/devices/0000:01:00.1/remove - - - - 1
This way, the dGPU no longer uses any power. You can verify this (while running on battery, of course) using:
awk '{ print $1*10^-6 " W"}' /sys/class/power_supply/BAT0/power_now
You should get around 6 W when you dim the display and have an idle machine.
If you want to get the dGPU back, for example to pass it into a VM, simply rescan the PCIe bus:
echo 1 | sudo tee /sys/bus/pci/rescan
This machine also has 3 different fan profiles: Normal, silent and turbo. I
personally like my machine to be entirely quiet and with the silent profile,
the fans turn off completly if there is no significant load. I also like to be
able to control the fan without needing to be root, from my regular user. To
achieve both, create a file /etc/tmpfiles.d/asus_fan.conf and
write the following into it:
z /sys/devices/platform/asus-nb-wmi/throttle_thermal_policy 664 root js - -
w /sys/devices/platform/asus-nb-wmi/throttle_thermal_policy - - - - 2
Important: Replace js with your username!
Once you have done that, you can use a script such as this to toggle through the profiles. I bind it to the fan key in GNOME and it even shows me a nice notification which profile I have selected.
Lastly, another feature of Armoury Crate is to not fully charge the battery to
extend its lifetime. I am not sure how much difference this actually makes,
alas, we can do the same on Linux. Just create a file
/etc/tmpfiles.d/asus_battery.conf and write the following into it:
w /sys/class/power_supply/BAT0/charge_control_end_threshold - - - - 60
Replace 60 with whatever maximum percentage you want to charge it to. Obviously, you can also change this on the fly, e.g. if you want to charge to 100% again as a one-off before leaving the house:
echo 100 | sudo tee /sys/class/power_supply/BAT0/charge_control_end_threshold
If you do that often, you might consider adding a z line similar
to what we did in asus_fan.conf so that you don't need
sudo.
That's it. If there's anything more you would like to do that Armoury Crate can do that I forgot about, please contact me and I'll have a look.
Actually secure boot on Fedora
Created: 12.08.2021 20:11 UTC
A few months ago I purchased a new notebook which supports Secure Boot. It is actually my very first machine with Secure Boot support on which I want to run Linux (the only other machine I have which supports Secure Boot is my gaming rig, which exclusively runs Windows as it has no other purpose than playing games).
While at first I was happy to finally have a somewhat secure boot chain, the disappointment came quickly: Pretty much all Linux distributions which support Secure Boot use a shim called shim which is signed with a key from Microsoft. shim then checks the signature of the kernel against certificates stored in an UEFI variable and failing that falls back to checking against the Secure Boot keys stored in UEFI. While I do believe that UEFI somewhat protects its own certificate store, I am not so sure about that of shim.
But this is not the only problem with the default Secure Boot setup on Fedora and most other distributions: The initrd is not verified at all! Yes, that's right - someone can just put a malicious initrd on your unencrypted /boot partition and there is absolutely nothing that prevents it from being loaded! The kernel and GRUB (at least by default) only implement the bare minimum for Secure Boot: Making sure that no unsigned code runs in kernel space while entirely ignoring everything that would compromize user space. That makes Secure Boot entirely useless by default, as compromizing the initrd is even much easier than comprimizing the kernel: Just swap the /sbin/init in the initrd with a shell script that opens a backdoor and then calls the real init instead of cumbersomely inserting a backdoor into the kernel.
So, is Secure Boot entirely useless? No! It is just that the way all Linux distributions use it by default is entirely useless, because their goal is to get everything signed by Microsoft so that users can boot the system without needing to reconfigure Secure Boot. Their goal lis not to be secure. But we can fix all of that! The idea is to combine the kernel, initrd and boot options into a single .efi file that we sign with our own key.
So first of all, we need to switch from GRUB to systemd-boot. But wait! Don't go follow any tutorial on how to do that - because we're doing things a bit differently. So why do we need to switch? GRUB is very hard to secure. It reads many unverified files and its configuration is by default entirely unverified. It also by default does not verify the initrd. With a lot of work and assembling your own GRUB, it is possible - but this is very error prone, fragile and GRUB recently changed things around so that all the instructions that you will find on how to let GRUB verify everything are outdated. systemd-boot on the other hand is simple: You take the systemd-boot stub, the kernel, the initrd and the boot options and merge it into a single .efi file that you then sign.
Now is a good time to have a Fedora DVD ready to boot in case you break something! Do not proceed if you have no medium to boot from for recovery!
To uninstall GRUB, do:
sudo rm /etc/dnf/protected.d/shim.conf
sudo dnf remove shim\* memtest86+
Do not reboot now! Your machine is in an unbootable state now!
Time to save the kernel boot options:
cat /proc/cmdline | cut -d ' ' -f 2- | sudo tee /etc/kernel/cmdline
Next, we need to generate a few keys. But first, let's look at what keys Secure Boot has:
This means you can import a DB or DBX from a booted system if it is signed with a KEK, and you can import a KEK from a booted system if it is signed with the PK. If you import it directly in the firmware (we will do this later), no such signature is needed. But you still need a PK and KEK, as otherwise Secure Boot will remain in setup mode - meaning the OS can import keyes without requiring a signature.
We need to generate our own PK, KEK and DB. To generate those keys, we do the following:
sudo dnf install openssl
sudo mkdir /etc/secureboot
sudo chmod 700 /etc/secureboot
sudo openssl req -new -x509 -newkey rsa:4096 -subj "/CN=$(hostname) PK/" -days 36500 -nodes -sha256 -keyout /etc/secureboot/pk.key -out /etc/secureboot/pk.crt
sudo openssl req -new -x509 -newkey rsa:4096 -subj "/CN=$(hostname) KEK/" -days 36500 -nodes -sha256 -keyout /etc/secureboot/kek.key -out /etc/secureboot/kek.crt
sudo openssl req -new -x509 -newkey rsa:4096 -subj "/CN=$(hostname) DB/" -days 36500 -nodes -sha256 -keyout /etc/secureboot/db.key -out /etc/secureboot/db.crt
sudo openssl x509 -in /etc/secureboot/pk.crt -outform DER -out /etc/secureboot/pk.cer
sudo openssl x509 -in /etc/secureboot/kek.crt -outform DER -out /etc/secureboot/kek.cer
sudo openssl x509 -in /etc/secureboot/db.crt -outform DER -out /etc/secureboot/db.cer
sudo sh -c 'cp /etc/secureboot/*.cer /boot/efi'
We won't need the unencrypted /boot anymore, so let's move /boot to the encrypted root partition so that nobody can swap the kernel or initrd on the unencrypted /boot partition and trick us into signing it later.
sudo umount /boot/efi
sudo cp -a /boot /bootx
sudo umount /boot
sudo rmdir /boot
sudo mv /bootx /boot
sudo mount /boot/efi
sudo -e /etc/fstab # Remove /boot from it, but not /boot/efi
In order to automatically merge systemd-boot, the kernel, initrd and the boot options into a a single .efi file and sign it when a new kernel is installed, I wrote a kernel-install hook. All you need to do is drop 100-combine-and-sign.install into /etc/kernel/install.d and make it executable. After adding this file, do the following and you should end up with everything as a single, signed .efi file:
sudo dnf install systemd-boot sbsigntools binutils
sudo mkdir -p /boot/efi/EFI/Linux
sudo dnf reinstall kernel-core-$(uname -r)
That's it from the Linux side. Now it's time to go into your UEFI settings: Change the file to boot to EFI/Linux/linux.efi. Then clear all existing keys (PK, KEK and DB - you can also clear DBX, as it is now useless: it only contains hashes you could not boot anyway) and import the PK, KEK and DB that we copied to the EFI partition (you can and should delete those from the EFI partition after importing them). And obviously, set a UEFI password (but if you read this guide, you probably are the kind of person who already has that anyway, right?). If everything worked, your system should come up again now. Good luck!
If you like to clean up, you can actually get rid of all files in /boot/efi except for /boot/efi/EFI/Linux/linux.efi. Use dnf provides /boot/efi/foo to see which package added the unnecessary files and uninstall them.
Edit: Please see here if you are running Fedora 39, as things changed in Fedora 39, requiring changes to this process.
Incrementally exporting a Fossil repository to an existing Git repository
Created: 28.05.2020 18:48 UTC
As mentioned in my last blog post, I recently migrated ObjFW from Git to Fossil, while still keeping to commit to the Git repository, with an automatic conversion to Fossil.
This incremental and automatic export to Fossil worked well, but it was slow,
as the fossil import workflow always requires rebuilding of the
metadata, as otherwise a fossil pull would not pick up the
changes. Also, Fossil supports some nice features that Git does not, like
giving colors to branches, so I was missing out on these features by using that
workflow.
So I looked into committing to Fossil and exporting to Git instead. Which is
something that is supported out of the box using fossil git
export. However, it can only export to a new repository, not to
an existing repository. This would have meant I would have lost all Git history
and everybody would be required to delete their checkout and create a new one.
Not only is this rewriting history and cumbersome, but it also has the risk
that if there were problems during the conversion, the good state would be lost
forever.
Therefore, I looked into how to make this work with an existing repository.
Since this works incrementally, there has to be a way to keep state, right?
There needs to be a way to keep track of what Git commit matches what Fossil
commit. And that's exactly what the marks files generated by git
fast-export and fossil import do.
When I converted the repository to Fossil, I used the following (simplified, not the actual commands that I used since there were some hoops necessary to cross security boundaries on my server):
# This is important if there is any non-UTF-8 anywhere in the repository
export LC_ALL=C
git fast-export --all --signed-tags=strip --export-marks=git.marks |
sed 's/^committer Jonathan.*>/committer js <js>/' |
sed 's/^author Jonathan.*>/author js <js>/' |
sed 's/^tagger Jonathan.*>/tagger js <js>/' |
USER=js fossil import --git --rename-master trunk \
--export-marks fossil.marks repo.fossil
For later invocations, I then added --import-marks of the same
marks file to both git and fossil for the incremental
import. The sed invocations are necessary so that the commits get
the correct user js instead of the e-mail address being used as
the username.
The resulting marks files contain a mapping for mark id to Git commit and mark
id to Fossil commit. When using fossil git export to create a Git
repository again from the converted Fossil repository, I noticed that it
creates a .mirror_state/db file in the target Git repository. This
file is an SQLite3 database with the mapping between mark id, Fossil commit and
Git commit and is used for incremental Git exports. So I wrote a
small program that parses the
marks files generated during the initial conversion and later incremental
imports and generates the .mirror_state/db file for an existing
repository. After creating this file in the existing repository, a normal
`fossil git export` now just incrementally exports to the existing Git
repository without rewriting any history.
Now only one problem remained: fossil git export always uses
username@noemail.net as the committer name
(code).
This means the commits are not properly attributed on GitHub. I fixed this by
just hardcoding a fossil_strcmp() against js there
and then emitting my e-mail address instead. But of course the proper fix would
be to refactor the
code from
the deprecated export command to be reusable by the new export.
Finally, I set up a cronjob that runs every minute that exports from the Fossil repository to a checked out (important - exporting to a bare repository doesn't work!) Git repository and pushes that, to both my Git server and GitHub. This is fast enough to run it every minute, unlike the other direction (for which I hacked around the expensiveness of the metadata rebuild, which even happens when nothing changed, by doing some checks first if there's actually new commits since the last import).
You can see a Fossil commit here and the Git commit that was automatically created by this process.
New ObjFW homepage
Created: 23.05.2020 19:42 UTC
Today, I finally created a new homepage for ObjFW - by using Fossil!
The content is still mostly the same, but that will change in the coming days.
Fossil is a VCS that also comes with a wiki, ticket system, forum and many things more - all in a single binary and all part of the repository.
Since ObjFW is using Git, I had to convert the Git repository to Fossil. It was clear from the start that I will always need to have a Git repository, as that is what people are familiar with, but it was unclear whether I want to export the Fossil repository to a Git repository or the Git repository to a Fossil repository. Since converting from Git to Fossil went flawlessly (and I could even finally recover those old branches from the times of using Mercurial!), while I could not export back from Fossil to Git without rewriting all history (it cannot export to an existing repository), that is what I'm doing for now. There is a cronjob running that checks for new Git commits and adds them to the Fossil repository (currently every minute, but I might change frequency).
So, what does that mean for you, the user? What should you use? The answer is easy: It doesn't matter. Both repositories will be treated as first class citizens, so whether you use Git or Fossil is entirely up to you. But for issues, the wiki and forum: Please use Fossil and not GitHub. It's easy to create an account: Just click on login, then register and you're done! And almost all existing issues and wiki pages have already been moved over to Fossil!
This also means there's a forum now to discuss about ObjFW! Hopefully soon there will be some discussions there!
ObjFW 98 SE: Bringing Objective-C to Windows 98 SE and NT 4.0
Created: 17.05.2020 20:34 UTC
Yesterday, I got the idea to port ObjFW to Windows NT 4.0. Considering the lowest supported Windows version so far was Windows XP, this seemed like it would not be too much work. However, the biggest problem was getting a toolchain that still supports Windows NT 4.0!
Just using an old MSYS2 on Windows XP (I had a Windows XP VM around anyway for
writing
IPX/SPX[1,
2]
support) and copying the resulting binaries to Windows NT 4.0 did not work: It
complained about not having AddVectoredExceptionHandler and
RemoveVectoredExceptionHandler. Of course: According to MSDN,
those were introduced in Windows XP. Grepping the GCC sources did not yield any
results, but grepping the entire MinGW sources did: It's used in winpthread.
And luckily, it's only used for thread names, so commenting out two lines and
recompiling it was enough. winpthread is linked by GCC by default, because the
exception handling runtime needs it - and we really want exceptions for ObjFW.
After the compiler no longer created binaries that had missing symbols on
Windows NT 4.0, I got an OFInvalidFormatException loop: MinGW's
implementation of asprintf seems to call into
snprintf and expects it to return the number of bytes that would
have been written if a sufficiently large buffer were provided. But on Windows
NT 4.0, it only returns -1 if the buffer is too small. And trying to print the
error of course calls into it again, hence the loop. Unfortunately, my own
asprintf implementation relied on the exact same
snprintf behavior - it's part of the C89 aleady, after all! So I
had to work around it
- easy enough. After that, I was able to get a "Hello world" using
of_stdout and OFApplication:
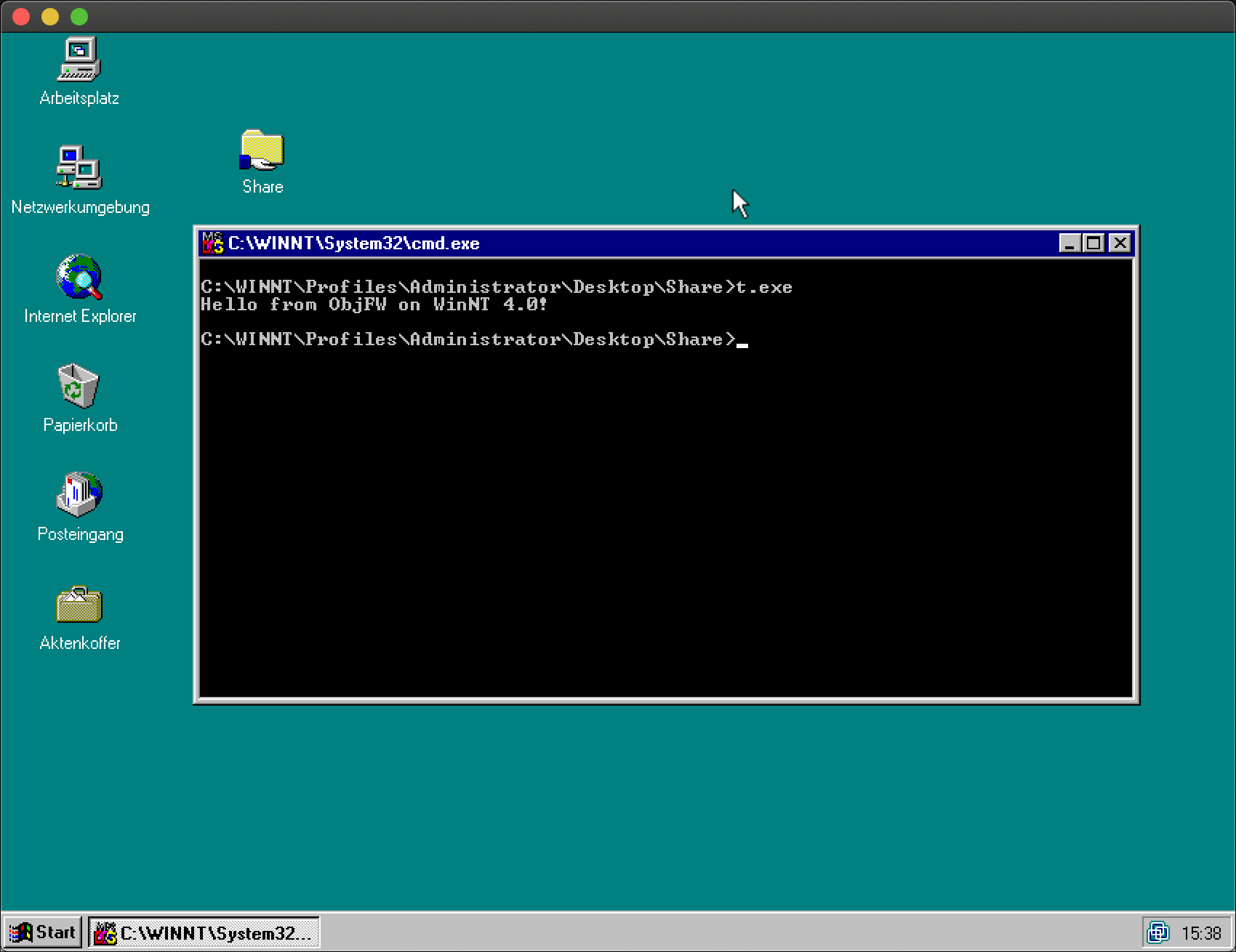
And a few minor changes later, all tests were running successfully:
Well, not all of them: I had to disable sockets, as with them, something would
try to load icmp.dll, which does not exist on Windows NT 4.0. I'll
look into that another time.
Later that evening, I wanted to take things further and thought: If we have
Windows NT 4.0 now, why not Windows 98 SE as well? This is more difficult,
though: Windows has two versions of almost every API: An A version
and a W version. A wrongly stands for ASCII, while
W stands for wide. Meaning the A version takes all
arguments in the native, locale-dependent codepage, while the W
version always uses Unicode. The W versions were only introduced
with Windows NT and ObjFW used the W versions exclusively. Since
the Windows console is quite bad and needs some nasty hacks
to be made bearable at all, it meant I could not even get a "Hello world"
without porting those hacks to the A APIs first. So I added a
fallback for when the
W version returns ERROR_CALL_NOT_IMPLEMENTED (all
W APIs return that error on Windows 95/98/ME), got a working
"Hello world" and called it a day (unfortunately I forgot to take a screenshot,
as it got quite late).
The next day, I decided that calling the W version first and only
falling back to the A version if it fails with
ERROR_CALL_NOT_IMPLEMENTED doesn't make a lot of sense: After all,
there is never gonna be a non-NT version of Windows that supports Unicode. So I
decided to add an API
to detect if ObjFW is running on Windows NT and
used that instead.
While I already had a "Hello world" working, it was not one using
OFApplication, but just using of_stdout in
main. So in order to get that working, I
ported
OFApplication to the A APIs and finally got a
proper "Hello world". So now it was time to
port everything else to
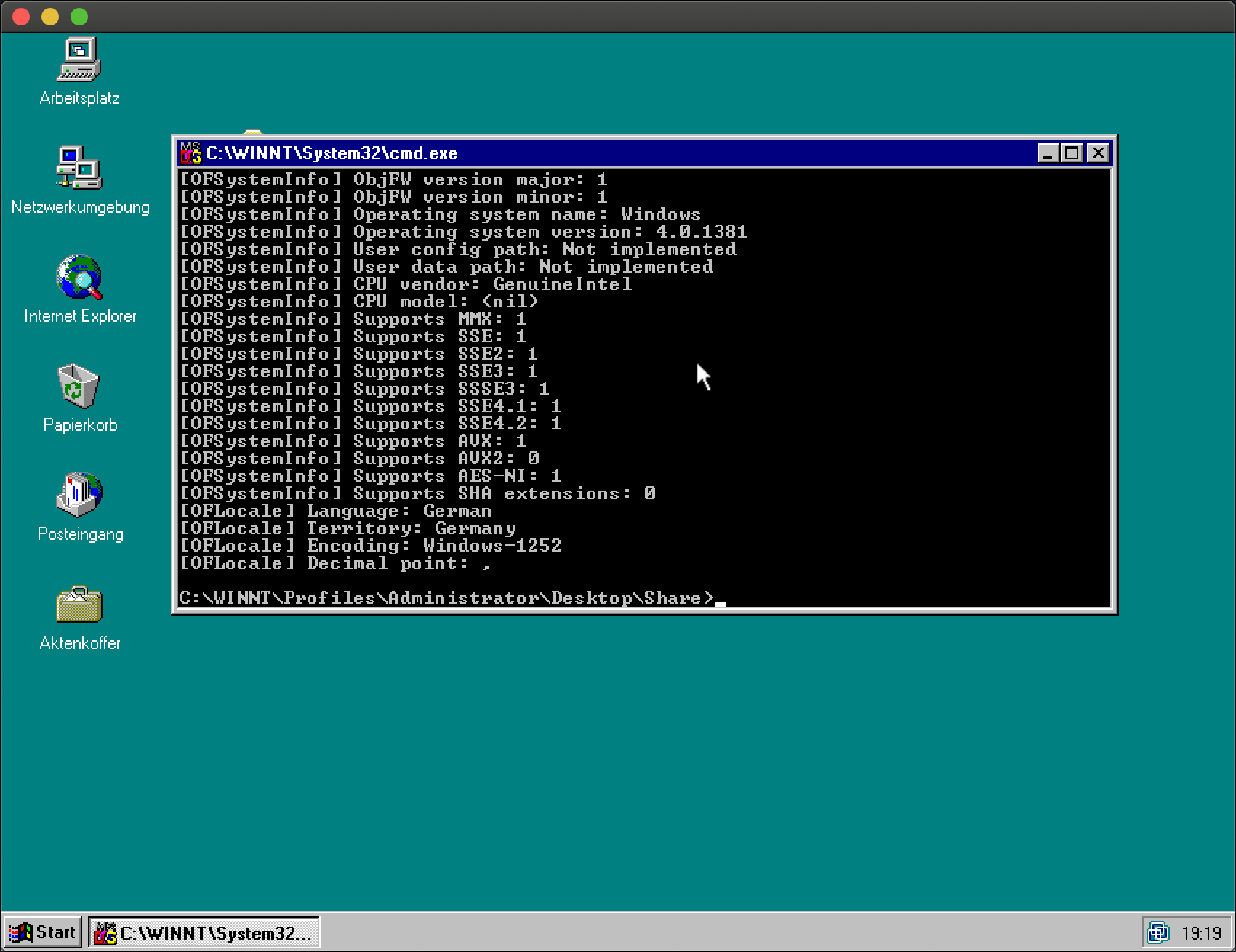
the A APIs and voilà, all tests are running successfully:
Well, not all of them: For Windows 98 SE, in addition to disabling sockets, I
also had to disable DLLs and threads. For DLLs, I have not figured out yet why
it doesn't work, but for threads, I already know what it is and how to fix it
(WaitForSingleObject does not support waiting for threads).
And the coolest thing: This now results in a binary that works on anything from Windows 98 SE to Windows 10, using all features as available!
I guess that's not too shabby for a weekend and I'll see that I get all the remaining issues fixed. And who knows, maybe ObjFW 3.11 for Workgroups is next? ;)
Bringing Objective-C to the Amiga
Created: 23.04.2018 00:30 UTC
After porting ObjFW (and at the same time Objective-C) to MorphOS and starting to port it to AmigaOS 4, I thought: It's nice to have Objective-C on a modern Amiga-like operating system. But what if we could have it on the real thing, the classic m68k Amiga? And thus, I ported it to AmigaOS 3 today.
First things first, we need a compiler. No compiler modern enough to support exceptions in Objective-C was released for the Amiga itself, as there was never any GCC 4 for Amiga. However, there's a new cross-compiler around: bebbo's amiga-gcc. This is the successor to his amiga-cross-toolchain fork, which unfortunately downloaded lots and lots of archives via plain insecure HTTP and would then go to execute downloaded files, so I never really wanted that on my system. But amiga-gcc checks out everything from GitHub, and the few files it downloads never get executed on the system you build the toolchain on. So after some minor patches to make it build on macOS, I had a toolchain.
Getting ObjFW to compile was easy. But running the resulting tests binary immediately resulted in "Program aborted". Huh, that was strange - I was already expecting exceptions not to really work, but then the first test using exceptions would usually fail and not an immediate abort. So now I had to figure out what was aborting - not an easy task without having a debugger in which I can just set a breakpoint and look at a backtrace. So the first thing to try was creating an empty binary that just links in ObjFW and its runtime, to see if all the initialization worked. That worked, so I added exceptions into the mix. Now I got the same "Progam aborted" as with the tests. So I moved on to to add a #define for abort to print the source file and line and then exit. The first theory was that one of the switches in src/runtime/exception.m fell through and then called abort(). But this didn't catch anything, meaning it's not in my code. Usual suspects then would be libc and libgcc. So I went ahead and added the same #define to the libgcc sources and finally found what called abort: uw_init_context(). Ouch, that's bad, that's pretty much the first thing called by _Unwind_RaiseException(). uw_frame_state_for() returned _URC_END_OF_STACK, making an assert in uw_init_context() fail. Well, that should never happen, unless our DWARF info is garbage. I had tried exceptions with C++ before, which worked, so I knew that unwinding couldn't be entirely broken. Looking at the assembly output of a small test program that just throws and catches in both C++ and ObjC, there was no obvious difference. After trying several things for hours, including rebuilding the toolchain with Obj-C++ support and trying that and switching from amiga-cross-toolchain to amiga-gcc, which all failed, I finally found a way to make it work: When using m68k-amigaos-g++ rather than m68k-amigaos-gcc, it would suddenly work. I had tried compiling it as ObjC++ before by renaming the the testcase to .mm, but that didn't work. But naming it .m and using m68k-amigaos-g++, it worked. I have not figured out why it works this way, though, but at least now I have something that works. And according to m68k-amigaos-nm, it does not even bring any unnecessary C++ code in.
Shortly after this was working, I had almost all tests work. Except one weird one where the serialization was breaking. After spending some hours on this, I finally found the culprit: I had added my own defines for PRI?{8,16,32,64}, as I was initially using amiga-cross-toolchain, but switched to amiga-gcc while debugging the exception problem. amiga-cross-toolchain lacked those, but amiga-gcc actively undefined them, redefining them the wrong way, truncating the result to 32 bit. The solution here was to #define __have_longlong64. And after some more fixes, I then finally got this:
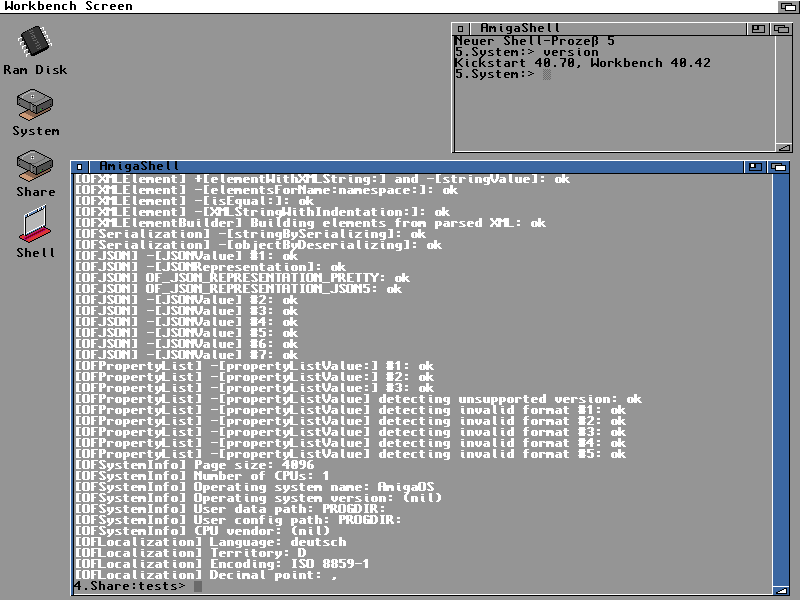
While this is already working, the porting effort to AmigaOS 3 is not done yet: I did not bother making sockets work yet and everything is still linked statically rather than having a .library. I will work on this in the coming days, but for working on it for only a day, I think this is enough progress :).
ObjFW 0.90.2 has been released
Created: 23.10.2017 21:40 UTC
I just released ObjFW 0.90.2.
As usual, you can get the tarballs and changelog here.
ObjFW, Frameworks, the App Store and Swift
Created: 20.10.2017 23:30 UTC
This week, I finally got scrypt-pwgen into the App Store (except France, because they have insane crypto regulations). This was actually quite a fun exercise, as this (to the best of my knowledge) is the first app to make it into the App Store that uses ObjFW. Initially, I was using ObjFW built as a .framework for this and it worked fine on my local device, but it confused the App Store a lot, and while the build would upload, it would then fail the processing on Apple's side. The immediate remedy was to just use ObjFW as a static library, which worked and pretty much let me get the app into the App Store immediately (except the first version being rejected, because it crashed as a category wasn't loaded due to the switch from a .framework to static linking). However, I really wanted this working with a .framework. Since copying the Xcode-built .frameworks over was annoying, I tried adding a subproject with ObjFW itself, but that was also annoying. I ended up adding support for building .frameworks to buildsys.mk and a script that builds a universal ObjFW.framework and ObjFW_Bridge.framework for all architectures + all simulator architectures, so that I can easily switch between device and simulator. This now works beautifully, and I can successfully upload it to the App Store, with just one caveat: Before uploading it to the App Store, I need to use lipo to strip the simulator architectures, as Apple does not like you uploading a .framework that contains support for unsupported architectures :).
All this looking into .frameworks gave me the idea to look into how well ObjFW.framework and ObjFW_Bridge.framework work with Swift. And after minor fixes, it worked exceptionally (pun intended!) well, except for one thing: Exceptions! But there was an easy solution, as Swift supports Blocks, and now there's a category on OFException in the bridge that allows you to do this:
import ObjFW
import ObjFW_Bridge
OFException.try({
OFOutOfMemoryException(requestedSize: 1234).throw()
}, catch: { (e: OFException) in
print("Caught \(e.class())")
}, finally: {
print("Finally")
})
So now it's even possible to use ObjC exceptions in Swift! Initially, I was converting OFExceptions into NSErrors, but while this is the most "native" mapping, it felt very ugly using it. The way it is now allows using it in a way that is almost the same as in ObjC.
ObjFW 0.90.1 has been released
Created: 20.08.2017 19:53 UTC
I just released ObjFW 0.90.1.
As usual, you can get the tarballs and change log here.
Interesting GCC optimization on SPARC64
Created: 19.08.2017 10:17 UTC
Today, I was looking into the following linker warning I got on OpenBSD/SPARC64:
/usr/bin/ld: warning: creating a DT_TEXTREL in a shared object.
This was in the runtime .so, so it was pretty obvious that this was coming from the hand-written lookup. readelf -r lookup-asm/lookup-asm.lib.o quickly revealed:
Relocation section '.rela.text' at offset 0x568 contains 6 entries:
Offset Info Type Sym. Value Sym. Name + Addend
00000000002c 000b00000029 R_SPARC_WDISP19 0000000000000000 objc_method_not_found + 0
000000000068 000c00000029 R_SPARC_WDISP19 0000000000000000 objc_method_not_found_ + 0
0000000000b4 000d00000011 R_SPARC_PC22 0000000000000000 _GLOBAL_OFFSET_TABLE_ + fffffffffffffffc
0000000000bc 000d00000010 R_SPARC_PC10 0000000000000000 _GLOBAL_OFFSET_TABLE_ + 4
0000000000c4 00060000000f R_SPARC_GOT22 00000000000000d4 nil_method + 0
0000000000c8 00060000000d R_SPARC_GOT10 00000000000000d4 nil_method + 0
Hm, yeah, that objc_method_not_found doesn't look right. Let's see what we have in the code (this is inside an assembler macro and \not_found is replaced with objc_method_not_found):
be,pn %xcc, \not_found
Ah, of course. While the linker handles a call fine in PIC mode, it apparently chokes on the branch if equal. Makes sense, considering the linker actually replaces the call with different instructions. And also explains why this warning did not appear on NetBSD/SPARC64: OpenBSD seems to have an older version of the linker due to avoiding GPL3 code.
Ok, so now we know what the solution is: Branch to a small stub instead that just does a call that then gets replaced by the linker. Let's see how GCC emits this if we want to have a tail call:
stub_func:
or %o7, %g0, %g1
call objc_not_found, 0
or %g1, %g0, %o7
This code confused me at first: Why is it setting %g1 to %o7? %g1 is volatile and the ABI doesn't specify anything about it at all. Also doesn't specify it in the PIC section. Why does it need to be set for the call? Is the ABI slightly different on OpenBSD? And why immediately set %o7 back to %g1? (Note: SPARC64 uses branch delay slots, so the instruction after the branch is executed before the branch is taken.)
This didn't seem to make any sense, until I found this in the ISA documentation:
The CALL instruction writes the contents of the PC, which points to the CALL instruction itself, into r[15] (out register 7) and then causes a delayed transfer of control to a PC-relative effective address. The value written into r[15] is visible to the instruction in the delay slot.
Aha! That's interesting. While it only says the value is visible in the branch delay slot, this also means that %o7 has already been set when we execute the branch delay slot. GCC exploits this in a nice way: It stores in %g1 the old value of %o7 and restores it during the call, meaning that the called function will get the same return address we had. This is why the volatile register %g1 can be used, as we don't even care about it anymore when the called function is executed, and why it sets it and immediately sets it back.
Anyway, since it just cost me 10 minutes to figure out why this code works and does what it should, I thought it might be worth blogging about this to save someone else those 10 minutes (as a quick search does not turn this up - hopefully it will now).
ObjFW 0.90 has been released
Created: 01.08.2017 14:34 UTC
I just released ObjFW 0.90. The big version jump is because the goal is to move towards a 1.0 release, as it is pretty stable now.
As usual, you can get the tarballs and change log here.
ObjFW on the Nintendo 3DS
Created: 20.03.2016 19:32 UTC
So, I bought a New Nintendo 3DS recently. Obviously, it did not take me long to port ObjFW to it. In fact, just a few days later, I had ObjFW working already, but there were still some minor issues. I fixed these minor issues now over the weekend and ObjFW is now fully supported on the Nintendo 3DS:
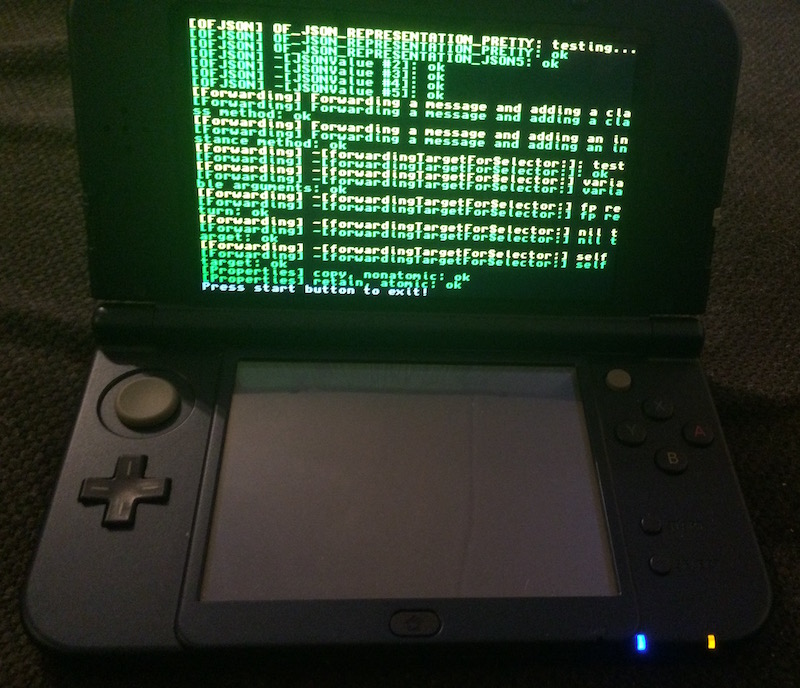
Sockets and threads are not supported yet, but I will add both very soon.
I did the initial development on 10.5.0-30E, but since then I downgraded my Nintendo 3DS to 9.2.0-20E so that I can always keep Homebrew, even if Nintendo releases an update that fixes the injection vectors. I start games in an emulated NAND which runs 10.7.0-32E now, which I start from my 9.2.0 using CakesFW, but run all Homebrew on the 9.2.0 (which allows kernel access). This way, I can use this device as a development device for Homebrew and to play all the recent games including online access.
New domain - new PGP key
Created: 28.12.2015 22:22 UTC
Since I have a new domain now (heap.zone) as the old one was not very international, I used that as an excuse to generate a new key with improved operational security. I will follow up with the details later, but the new key fingerprint is:
2438 8F8F 4A75 ECC4 FCBD E8C8 2DFF 526B B17F 76C6
The new key is signed by the old one, which is revoked now. The revocation also includes the fingerprint of the new key.
Objective-C 1 support dropped in ObjFW
Created: 29.11.2015 14:33 UTC
This weekend, I dropped support for Objective-C 1 in ObjFW and cleaned up the code a lot by making use of Objective-C 2 features. Objective-C 2 makes a lot of code much easier to read and the backwards compatibility to Objective-C 1 meant many features like properties, fast enumeration and optional protocols couldn't be fully used (they could be used by someone using ObjFW, but not in ObjFW itself).
The downside is that this increases the requirement from GCC ≥ 4.0 or Clang to GCC ≥ 4.6 or Clang. But since today even GCC 4.6 is quite old, there is no reason to still support even older versions, especially as this means making the code uglier, a lot even. A few platforms were dropped from GCC 4.6 that were still supported by GCC 4.0, but none of them are really interesting for ObjFW. The most interesting of these was BeOS, which can still be supported using a Haiku toolchain. The others were mostly old versions of OSes for which a new version exists that runs on the same hardware.
Apple GCC is unaffected by this: Apple's GCC supported Objective-C 2 since Mac OS X 10.5. This is noteworthy as this is the only compiler that works for OS X on PowerPC.
ObjFW 0.8.1 has been released
Created: 04.10.2015 12:35 UTC
I just released ObjFW 0.8.1.
As usual, you can get the tarballs and the change log here.
NetBSD on an x200
Created: 16.08.2015 08:14 UTC
I'm currently at the CCC Camp and bought myself a Lenovo x200 beforehand, as I didn't want to bring my MacBook Pro. Since I was in the mood for experimenting, I installed NetBSD on it, as it has been years since I last used NetBSD on a notebook (I'm using it on all my servers for more than a decade, though). To my surprise, everything worked out of the box and works perfectly. I didn't even have to hunt down a firmware for the WLAN chip, everything just worked. I even had hardware accelerated 3D support without any blobs, out of the box. The only thing I haven't gotten to work yet is standby. Well, technically, standby works - I just cannot get out of standby and have to power down the machine then.
I bought the x200 specifically because I wanted to flash CoreBoot on it, The x200 is pretty much the newest machine that works with CoreBoot without any blobs. I got some cables soldered on my SPI flash now and a connector soldered to the other end of the cables (thanks to zaolin!), but I haven't gotten to actually flashing it yet. It will be interesting to see how well the combination CoreBoot + NetBSD works, and if that maybe actually fixes my standby, as CoreBoot doesn't ignore the ACPI standard like Lenovo does. I'll definitely write another blog post once I got CoreBoot running.
ObjFW 0.8 has been released
Created: 14.08.2015 18:46 UTC
After way too long time (over 2 years since the last release!), I finally released ObjFW 0.8 just minutes ago. The differences to the previous release are bigger than ever and I recommend to read the changelog and strongly urge everyone to upgrade. As usual, download and changelog are here.
New PGP key - again, but this time on a Gnuk
Created: 13.02.2015 21:57 UTC
So, I changed my PGP key - again, I know. But there's a good reason for it: I now have my new key on a Gnuk. Well, to be more correct, on an FST-01 running Gnuk. The FST-01 is a small ARM board in the size of a USB stick that is based on an open hardware design. And Gnuk is a GPLv3 licensed implementation of the OpenPGP card specification for the FST-01.
After receiving my FST-01, I quickly realized how hard it is to actually generate a key in a secure environment from which I can then transfer it to the Gnuk. Since one of my requirements is to use Ed25519 for the signing key (as I want to sign all my Git commits and thus want small signatures), I had to update the FST-01 to Gnuk 1.1.4 first. And I had to update GnuPG to include a few fixes for GnuPG + Smartcards (while the Gnuk is not a smartcard, it behaves like one and speaks the OpenPGP card protocol). But how to do all that in a secure environment?
So I came up with a plan: I downloaded the latest ArchLinux install image, as it comes with at least GnuPG 2.1, which means I can at least generate an Ed25519 PGP key. I burned that on one machine, then verified the CD in another that was already running ArchLinux and thus had the ArchLinux key ring and then booted it on a third machine - just to make sure. It's important to note that I removed all hard drives and network connections from the machine I booted it on (and of course used one without (U)EFI or other things for sneaky backdoors - and just to be sure even disabled loading of the microcode updates in the boot loader).
Once I booted it, I generated a 4096 bit RSA certification key (the idea being that a.) everybody can at least import and sign my key and b.) every keyserver can handle it and thus can get the missing Ed25519 key on the next refresh as my key specifies a keyserver that can handle Ed25519), an Ed25519 subkey for signing, a 4096 bit RSA key for encryption (since Curve25519 support for encryption isn't there yet) and an Ed25519 key for authentication (useful for SSH!) and stored all keys on a USB thumb drive. After that, I removed the thumb drive and attached another thumb drive to which I only copied the public keys (so I can copy those to the machine with which I want to use the Gnuk). Then I shut down the machine and waited until enough time passed to make sure all contents of the RAM are gone.
Once enough time passed, I booted it again and this time gave internet connectivity to it. I then downloaded the necessary cross-compilers and Gnuk and applied some patches (and of course verified the hashes for all of them!). The ”applied some patches“ part is the result of several iterations of doing this, since I discovered 2 bugs which were quickly fixed. Once the firmware was built, I would flash it to the Gnuk, then plug in the Gnuk and set the signing and authentication key type to Ed25519.
Now I once again rebooted the machine with internet connectivity, downloaded the GnuPG sources, verified the tarball, applied the necessary patches (after verifying their hashes!) to it and rebuilt it. After that, I unplugged internet connectivity and plugged in the USB thumb drive with the private key and finally imported the signing key, encryption key and authentication key to the Gnuk with the patched GnuPG (note that the certification key is missing - this is because the OpenPGP card protocol has nothing for it and to further improve security as this is the only long-lived key; the subkeys can easily be replaced). Don't forget to change the Gnuk's PIN, though!
Since this is all quite a lot of manual work, especially as you need to mount tmpfs all over the place etc., I created scripts for the steps for which you need internet connectivity anyway: For building the Gnuk firmware and for building the patched GnuPG. These scripts will download everything that's required and verify all hashes, but obviously, you should check the scripts first and make sure the checksums in there are correct!
While the whole process right now feels like a lot of work, it really isn't that much work anymore with those two scripts. Things should only get better over time, as a new ArchLinux ISO will at some point contain a GnuPG with all the patches (GnuPG 2.1.2 has already been released and contains all the necessary patches) and the FST-01 will at some point most likely ship with a newer version of Gnuk.
In any case, when carefully doing everything in this order and exactly like written, there is no point where the private keys could leak into the internet (or some non-volatile storage other than the thumb drive holding the private key, because none is attached!).
Oh, and of course, here's my new fingerprint:
6CBB 47F8 A2BB F84D 9C54 1868 6795 57FE 2FF7 C07A
It will be used to sign all commits from now on.
By the way: The FST-01 can also be used as a true random number generator. The software for that is called NeuG.
Edit: I should note that you should not order the FST-01 with the shrink tube, as you cannot access the SWD port there! And I should also note that RSA 4096 takes 6 - 8 seconds on the FST-01. I consider this an advantage, though, as you then notice if something is signing / decrypting when it shouldn't, as the FST-01 has a blue LED that is lighting up when it signs / decrypts.
Edit 2: I noticed that basically all the entropy is coming from haveged on the ArchLinux install CD. I really don't trust haveged (a quick web search reveals a lot of reasons why you really shouldn't), so I decided to flash NeuG to my FST-01 and use that to add more entropy to the pool (after killing haveged and draining all the entropy it generated). Since rngd is not part of the install CD, this means I had to download it before I could generate the key. While this is a disadvantage security wise (because for that I was connected to the internet for a brief moment), I consider the risk low enough and the advantage of having a TRNG far outweights it.
In any case, the fingerprint of the new key generated with some randomness coming from NeuG is:
2D73 E456 EE94 12BC 9077 78DF 78D4 EEEF 482C B982
New GPG key
Created: 11.01.2015 00:47 UTC
I have a new GPG key now (signed by my old key). This key is a little bit special, though, as it requires at least GnuPG 2.1.
The reason for this is that it uses Ed25519 for the main key and RSA 4096 for the encryption key. Unfortunately, it's not possible yet to use Ed25519 for encryption, but this is expected to change soon with a new GnuPG point release. Another disadvantage is that most key servers are not able to handle such keys yet, but the software for the key servers already has support for Ed25519 keys commited, so all that's needed is that operators upgrade.
While this has a lot of disadvantages, I decided to give it a try anyway, as I think this is the right way to move forward. While ECC with the NIST curves has already been specified in an RFC, using Ed25519 so far has not. There is a draft from Werner Koch though and since GnuPG already implements it, I'm sure this is only a matter of time.
Another nice side effect of using Ed25519 is that signatures are much shorter, allowing me to sign every commit I do. I'm not sure yet whether I will sign ObjFW releases with the same key or with a new key signed by this key. Having a release signing key has the advantage that it's much harder to compromise that key, as it's only rarely used.
Edit: This seems to be a key server accepting Ed25519 keys.
Edit 2: I also have a 4096 bit RSA key now, in case you absolutely cannot upgrade to GnuPG 2.1 for whatever reasons (though you should, as even the old algorithms were hardened there). I will use both keys, but I will sign all my commits only with the Ed25519 key to keep the sizes of the repos reasonable, so if you want to verify those, you have no choice but to upgrade.
My Ed25519 and RSA key sign each other and their fingerprints are:
Ed25519: E8F4 B5D1 607C 6DDB A3C6 FA41 D8C2 8F99 13CE F75C
RSA4096: 2FA4 A252 B8DC C53A 1D34 E2E1 BD90 B760 3030 94D7
Keep in mind though that you should not completely trust the fingerprints you see here, as they are only as secure as TLS and the webserver are - and we all know TLS is not really secure.
Edit: The keys have been replaced.
ObjFW on bare metal ARM Cortex-M4
Created: 16.07.2014 14:55 UTC
Yesterday, I received a mail from Shotaro Uchida letting me know that he successfully ran ObjFW on a ARM Cortex-M4 board, namely the Silabs EFM32WG-DK3850. He even included a screenshot, but unfortunately it isn't that spectacular as there's not much indicating it's indeed running on an ARM Cortex-M4 board - maybe a more spectacular screenshot will follow, we'll see :).
Uchida even was so kind as to let me know what he changed. It turns out that most changes were just hacks to make his build environment behave and that ObjFW pretty much ran out of the box. We're currently working on getting it to work without any changes by fixing his build environment (it's currently a mix of GCC and Clang with Clang not properly integrated) and passing the right options to ./configure. His changes can be found here.
It's always great to see what others do with ObjFW and it fills me with joy to see people trying ObjFW on new platforms. Thanks a lot for sharing this, Uchida! I think this is a nice demonstration of how portable ObjFW really is. How many frameworks run almost out-of-the-box on bare metal? ;)
Edit: Shotaro sent me the specs for that Cortex-M4 and it's comparable to the Nintendo DS.
Edit 2: Shotaro has written a blog post about ObjFW on bare metal Cortex-M4.
ObjFW ported to Nintendo DS
Created: 27.04.2014 19:50 UTC
I just committed the initial port to the Nintendo DS. It's still lacking threads and sockets, but I plan to add those eventually. Also noteworthy is that you require an argv-compatible loader in order to use files. Unfortunately, there is nothing I can do about this, as this is a limitation of the SDK.
Anyway, a picture is worth more than words, so here's a picture of ObjFW's tests all running successfully on my girlfriend's sister's DS (I did most of the development using DeSmuME, since I own no hardware):
Oh, and this is most likely the device with the lowest hardware specs on which I ever tried ObjFW. Yet it's still quite fast! :)
Mobile optimization of the blog
Created: 29.09.2013 18:29 UTC
Today, I optimized the blog for mobile devices so that it is possible to read it without scrolling. This also introduces a nicer way to declare code blocks, so that those are still scrollable, but as a block that scrolls instead of the whole page. Previously, those were only <code> tags, but for scrolling, a <div> is needed.
So far, I only tested it with an iPhone 4, but it would be nice if others could test it with different devices and let me know their results.
As usual, the code has been already updated and can be found on the usual place.
Finding the origin of an unhandled exception
Created: 23.09.2013 10:09 UTC
As you might have read here before, ObjFW gained support to show backtraces on unhandled exceptions some time ago. This makes it easier to find where an exception was thrown first, as there are a lot of places where exceptions are caught, some cleanup done and then rethrown. Using just gdb, only the place of the last rethrow would be shown in the backtrace, but due to ObjFW generating a backtrace when the exception is created and storing it inside the exception object, it is possible to find out where the exception was created.
However, if you run the application in gdb now, you get ObjFW's nice output of the backtrace from when the exception was created, which contains the addresses and function names, but not the source lines. So this seems like a step forward (getting the place where the exception was created) followed by a step backward (no source line anymore) at first.
But this is not the case. When running an application inside gdb, you can still get the source line, even if the backtrace is outputted by ObjFW and not by gdb. The trick is to use ObjFW to output the backtrace and gdb to resolve an address to a source line. In order to view the source line in gdb, just use list *0xdeadbeef, where 0xdeadbeef is the address as outputted by ObjFW. Notice the * before the address, it is important and may not be omitted.
I hope this explains how you can use ObjFW's ability to output a backtrace in conjunction with gdb to easily find out the source code that created the exception.
How @""-literals work
Created: 02.08.2013 10:54 UTC
I was recently asked how the @""-literals work in the runtime and in ObjFW, which resulted in a lengthy explaination which I thought might be worth blogging.
Whenever the compiler finds a @""-literal like @"foo", the compiler first creates a struct for that string which looks like this:
static struct {
Class isa;
const char *string;
unsigned int length;
} constant_string_1 = { Nil, "foo", 3 };
This is basically an object which is not allocated on the heap, but resides in section .data and does not have its isa pointer set. As the isa pointer needs to be set correctly, some initialization is required by the runtime, for which the compiler creates another struct which looks like this:
static struct {
const char *class_name;
id instances[3];
} static_instances = {
"OFConstantString",
{
(id)&constant_string_1,
(id)&constant_string_2,
NULL
}
};
A pointer to static_instances is then stored in the symtab. The symtab contains pointers to all selectors used in the compilation unit, pointers to the structs for all classes implemented in the compilation unit, pointers to the structs for all categories implemented in the compilation unit and pointers to all static instances in the compilation unit, together with the number of classes and the number of categories. All pointers except the pointers to the selectors are stored in a single array. The first class is at index 0, the first category at index cls_def_cnt (the number of classes) and the first list of static instances at index cls_def_cnt + cat_def_cnt (the number of categories). Of course, there can be multiple lists of static instances, as not all static instances need to be of the same class, but in practice, they usually are. After the last list of static instances, the array is terminated with a NULL pointer.
This symtab is then pointed to by the module struct, which is a struct generated for every compilation unit that uses Objective-C. The module struct also contains the ABI version for the structs it references, the name of the compilation unit (this is usually unused) and its size.
Finally, the compiler emits a function that is declared with __attribute__((constructor)) which looks like this:
static void
init(void)
{
__objc_exec_class(&module);
}
__objc_exec_class is a function of the runtime that parses the module, the symtab, the classes etc. and of course also the static instances. It keeps a list of all static instances for which it could not resolve the class yet, as it is possible that a compilation unit containing static instances of class Foo is registered before the compilation unit containing class Foo is registered. Each time a new class is registered, the runtime checks that list to see if there are static instances whose class just became available and initializes them if that's the case. Eventually, all compilation units were registered and the runtime resolved all classes for the static instances, so that all static instances are valid objects.
While from the perspective of the runtime everything is done now, there is still some more to be done in ObjFW: As the object generated by the compiler and initialized by the runtime does not contain more than the C string and the length, it is necessary to calculate missing information like whether the string is a valid UTF-8 string, its unicode length, etc. In order to do this, instances of class OFConstantString call -[finishInitialization] on any message sent to it and then resend that same message to self. -[finishInitialization] calculates the missing information and class-swizzles the object to class OFString_const, so that the resending of the message in OFConstantString actually calls the correct code instead of doing the initialization again.
After all this, the @""-literal is finally fully initialized and behaves just like any other OFString
All structs used by the runtime can be found in src/runtime/runtime-private.h. The structs prefixed with objc_abi_ are the ones emitted by the compiler, while all that are only prefixed with objc_ are those used by the runtime. The structs generated by the compiler are actually not documented, and other runtimes don't use the strict separation between ABI structs and runtime structs: They only declare the runtime structs so that for example a class name string is stored in a Class variable and they just fix it in-place, while ObjFW's runtime uses two structs that point to the same data; the objc_abi_ structs are used before initialization and the objc_ structs after. This results in having structs that are exactly what the compiler emits and not adjusted to the runtime, so that runtime-private.h is actually what comes closest to a documentation of the ABI. (And yes, creating those struct declarations sometimes felt like reverse engineering something proprietary, as there was no documentation ;).)
PS: This is also the 100th blog post! :)
Sockets on the Wii
Created: 13.06.2013 01:46 UTC
I already committed initial support for sockets on the Wii yesterday, however, there were still a few bugs as mentioned in the commit.
In the commit message, I wrote that I was undecided whether I want to add workarounds in ObjFW or whether I want to fix the SDK. Today, I decided to do both and went ahead and implemented the workarounds in ObjFW while filing bugs for devkitPPC.
The first bug in the list was that binding to port 0 does not work on the Wii. I worked around this by having a variable start at 65532 which is decremented on each bind. This works as nothing else should be running on the Wii while executing homebrew code. However, it imposes a restriction to not manually bind to very high port numbers. The variable starts at 65532 as 65533 and 65534 are used by OFStreamObserver for the cancel socket and using the last port just didn't feel right.
The second bug was that gethostbyname() does not work for IPs. I looked around in the POSIX specification and found out that this behaviour is indeed not required by the standard, but it seems to be what everybody else does (at least I couldn't find any OS not accepting IPs for gethostbyname()). As this was not 100% standards compliant anyway, I decided to add some extra code that tries to parse the host string using inet_addr() first and only falls back to gethostbyname() if the former failed. If you are scared because you just read gethostbyname(): Yes, the SDK only provides that, even though the IOS seems to provide getaddrinfo(). And no, gethostbyname() is never used if getaddrinfo() is available ;).
For the two remaining bugs, the workarounds were quite simple:
gethostbyname() simply isn't needed anymore, as we don't bind to port 0 anymore on the Wii, but use our variable instead and thus don't need it anymore to find out to which port the socket was actually bound to. And the addition of the missing struct sockaddr_storage isn't even worth mentioning.
So, after these commits, sockets work with the vanilla devkitPPC SDK for the Wii.
_Unwind_Backtrace()
Created: 11.06.2013 23:05 UTC
As I already wrote in the edit of the previous blog entry, __builtin_return_address() will crash on many platforms under certain conditions. As a result, it was disabled on all architectures except PPC (this was the only one that seemed to work reliable with it) and backtrace() was used instead if available. However, backtrace() seems to be only available on systems with glibc and OS X.
Today, I stumbled upon _Unwind_Backtrace(), which is part of libgcc_eh. The disadvantage of this function is that it only works if unwind tables exist and has no fallback like backtrace() does. However, as ObjFW code always has unwind tables since it uses exceptions, this is no problem at all and the ideal solution: It is available on all systems that support ObjFW (because we already need the other _Unwind_* functions for exceptions, it does not work without libgcc_eh or an ABI-compatible replacement lib anyway).
I just implemented backtraces using _Unwind_Backtrace() in ObjFW and removed the code for __builtin_return_address() and backtrace(), as those have no advantage anymore. This means that backtraces are now available on all platforms supported by ObjFW and shown when an exception is not caught!
Backtraces for Exceptions
Created: 22.05.2013 21:42 UTC
I just implemented backtraces for exceptions. While at first, this does not seem to be worth the effort (especially if not using backtrace() from execinfo.h in order to be portable and not limited to platforms that aim to be compatible to glibc) as every debugger can do it, this has a huge advantage over using a debugger: It gets the location of where the exception was created rather than the location of where it was thrown!
But why does it make a difference if we get a backtrace when the exception is created or when it is thrown? Well, a common problem why many exceptions are hard to trace is that there is a lot of code that catches an exception, does some cleanup and then rethrows it. Using a debugger, you get the location of the last rethrow. But this is not where something actually went wrong! But if the backtrace is generated when the exception is created and then stored inside the exception, you can always get the backtrace of when the exception was created - which is what you're usually interested in.
And finally, to add even more convenience, the default handler for unhandled exceptions now also shows the backtrace from when the exception was created.
Edit: I had to partly revert it, as it turns out that __builtin_frame_address() just crashes on many platforms instead of returning NULL, like the documentation said. I should have expected this, considering that just crashing is what most of GCC's builtins do on many platforms… See here for details.
ObjFW on the Wii
Created: 27.04.2013 00:14 UTC
It's been quite a while since I last blogged something that's not a release announcement, so I decided that I'm going to use this blog in the future to give a report on the status of my projects. Today, I am going to show some progress I made on ObjFW in the past few days.
Recently, I got a Wii for 50€ from eBay. It was sold as being broken, though it
really wasn't (the DVD drive was said to not accept any discs, however, simply
using a small screw driver to push it in worked. After that, even ejecting it
and inserting a DVD the normal way worked). So it was only a matter of time
until I ported ObjFW to it. At first, I was stuck with weird crashes, which
turned out to be a typo in OFSystemInfo and resulted in it always
returning 0 as page size. Of course, in a lot of places, the page size is used
to allocate a buffer, and naturally, this would fail. But still, it was hard to
find out that this was causing the crashes, so it took me some time. After
that, the rest was easy. I added a lot of new checks to configure in order to
have it easier to port ObjFW in the future (there were a lot of places were it
was assumed that it's a POSIX system if it's not Win32
- this is no longer the case now) which are already in Git. I even have code
here that sets up a console and waits for some input after all tests have
been run (otherwise, it would return to the Homebrew Channel without having a
chance to read anyting) and it also pauses the output until a button is pressed
if a test failed, so that those aren't missed. However, this code is not in Git
yet, because I still need to implement file system access and tests requiring
files are just disabled for now. After that, I will commit it and implement
threads and sockets (so for now, --disable-threads and
--disable-sockets are required).
Anyway, a picture is worth a thousand words, so here's one of my Wii having
successfully ran all ObjFW tests (except files, sockets and threads, of course
- but I'm confident those will follow in the next few days):
Edit: The Wii port is now committed. However, threads and sockets are not implemented yet, but files are.
Clang 3.2 has been released!
Created: 21.12.2012 16:54 UTC
Yesterday, Clang 3.2 has been released, which incorporates all of my patches for Clang. This is great news for ObjFW, as this means Clang 3.2 is the first release with the -fobjc-runtime=objfw option, which makes it possible to support all features and optimizations of the ObjFW runtime (for example ARC, the new ObjC literals, direct class references, etc.).
Before the Clang 3.2 release, it was necessary to get Clang from trunk and manually compile it in order to be able to use all of ObjFW's features. As distributions will start to integrate Clang 3.2 soon, this means you can soon install Clang from your distribution and use all ObjFW features without having to worry about compiling Clang yourself. This should greatly simply setting up ObjFW with all features.
Special thanks go to John McCall from Apple here, who made the architectural changes to Clang to have an -fobjc-runtime= switch, which made it possible for me to implement -fobjc-runtime=objfw and add a new class for targetting the ObjFW runtime to Clang. He also was the one who reviewed and committed most of my patches.
ObjFW 0.7.1 has been released
Created: 12.11.2012 11:26 UTC
I just released ObjFW 0.7.1.
As usual, you can get the tarballs and the change log here.
ObjFW 0.7 has been released
Created: 27.10.2012 16:35 UTC
I just released ObjFW 0.7.
As usual, you can get the tarballs and the change log here.
Secure anonymous Git access
Created: 03.10.2012 11:25 UTC
Today, I setup the smart HTTPS protocol for Git in order to allow secure anonymous access to the repositories hosted at webkeks.org. They can be reached under the URL
https://webkeks.org/git/$repo.git
now.
As the git daemon for the unencrypted Git protocol was always a pain, I disabled it now that there is an alternative, so please update your local checkouts the the new URL.
Those who had trouble with a corporate firewall blocking the Git protocol should be able to clone the repositories now, so that's another advantage.
Why I changed to Git after hating it
Created: 19.03.2012 20:08 UTC
Many might remember all the rants about Git from me, so for them, this might come as a surprise, but: Today, I switched a few of my repositories to Git, including ObjFW.
The rationale behind this is that most people know Git these days and DVCS equals Git for them, which means people are more likely to contribute if a repository is a Git repository, but also leads to software only supporting Git and not Mercurial. This also means the manpower behind Git has grown a lot, in fact, it has grown so much that Mercurial has trouble catching up with Git. This means Git offers a lot of nice features which Mercurial is missing unfortunately.
So, I played with Git a few days and found out that after getting used to it and creating a few aliases, it's actually usable. The trouble of learning how things are done differently in Git (mostly worse) pays off due to the features Git offers over Mercurial.
With the switch to Git, there also comes a new web interface here at WebKeks.org, which looks much nicer (see here) and which supports syntax highlighting - even for Objective-C.
Blog software updated
Created: 01.03.2012 16:46 UTC
I just updated the blog software and cleaned up the code a little.
While the code cleanup isn't that interesting, I noticed an interesting fact with blog aggregators that are often called "planet":
I noticed that some of them (namely Planet Symlink) are not able to differentiate between the <updated> and the <published> tag, which resulted in Planet Symlink showing old entries at the top again, just because the <updated> tag was changed. You can currently see all of my past blog posts there, again.
It even got worse: One might accept the fact that it orders by the <updated> tag, and some might even consider that a feature (IMHO, it's not a feature, as it just kills the timeline…), but it actually said on the website that the blog post was created at the date specified in the <updated> tag. Did they never read the ATOM spec to see the difference between <updated> and <published>?
Anyway, the blog update is done. The code I published has already been updated. If you happen to use it and want to use the updated code, keep in mind the date format changed to a more sane one (in the past, it was just copied from the data file, never parsed - it's parsed now. And be sure to have a 1 second delay between updating them, so weird newsreaders don't get confused by two entries having the same <updated> tag). This is also the reason why the <updated> tag changed for all blog posts, as I had to adjust them all.
ObjFW 0.6 has been released
Created: 27.02.2012 14:05 UTC
I just released ObjFW 0.6. This time, the differences are really huge and I highly recommend reading the changelog. As usual, download and changelog are here.
ObjFW 0.5.4 has been released
Created: 30.08.2011 16:45 UTC
I just released ObjFW 0.5.4. As usual, download and changelog are here.
ObjFW 0.5.3 has been released
Created: 30.06.2011 23:53 UTC
I just released ObjFW 0.5.3. As usual, download and changelog are here.
Git? Igitt!
Created: 26.04.2011 12:10 UTC
Today, I gave Git another try since we are using it at university and I'm currently looking into Mac Homebrew (MacPorts is starting to get reeeeally annoying), which is also using Git for everything. But after only 5 minutes, I noticed again how unbearable it is and how much pain even simple stuff is with it.
Since I'm a Mercurial fanboy, I of course know about hg-git. I already used it for simple stuff and it worked great. But I never had to push to a Git repository with branches so far, so I was amazed today about how well it works. Git branches are translated to Mercurial bookmarks and if you just hg up to the bookmark and do a commit + push, it actually goes to the right branch in Git.
So, if you too think that Git is a huge PITA and prefer Mercurial, give hg-git a try and don't bother with Git anymore.
PS: If you are wondering about the subject of this blog entry: “Igitt” is German and means “Yuck!”.
ObjFW 0.5.2
Created: 25.04.2011 18:50 UTC
ObjFW 0.5.2 has just been released. As usual, the download is here and the change log here.
ObjFW 0.5.1
Created: 21.04.2011 11:29 UTC
ObjFW 0.5.1 has just been released. As usual, the download is here and the change log here.
ObjFW 0.5
Created: 09.04.2011 20:41 UTC
ObjFW 0.5 has just been released. As usual, the download is here and the change log here.
ObjFW on the PSP
Created: 10.02.2011 21:13 UTC
I just ported ObjFW to the PSP. There were quite a few oddities and bugs on the PSP I had to fix or work around (like fix a broken libobjc, work around a broken asprintf, etc.), but it finally works.
Of course, I had to post a "screenshot":

Don't be confused about the OFXMLElementBuilder test being between those OFXMLParser tests: The reason is that the PSP wraps from the last line to the first and does not scroll, so everything is as it is supposed to be.
Change of language
Created: 07.02.2011 22:41 UTC
Seeing how little I posted lately and considering that some of the stuff I have been working on recently might be interesting for a broader international audience, I decided to change the language of my blog to English.
I'm going to mostly talk about ObjFW, Objective-C and XMPP here. Attending FOSDEM this year has shown me that there's clearly interest in these topics, so this is what I'm going for.
Also, in the past, it happened a few times that I wanted to point people to a specific blog post, but they did not understand German, so this problem is solved now as well.
It might still happen that I will post stuff in German, though, but this is most certainly stuff that only affects German-speaking people anyway.
Edit: Is there interest in translating previous posts? If so, feel free to mail me!
Quellcode des Blogs
Created: 09.01.2011 22:09 UTC
Da ich jetzt schon öfter nach dem Quellcode des Blogs gefragt wurde, habe ich mich entschlossen, den mal zu veröffentlichen. Allerdings kann ich den eigentlich niemanden empfehlen: Das ganze ist schnell dahingehackt, damit es seinen Zweck erfüllt. Alles andere als sauber. Aber da auch Templating etc. gemacht wird und da scheinbar einige Interesse dran hatten, mach ich's jetzt eben mal öffentlich.
Also, hier die entsprechenden Files:
Blog.m
Makefile
templates
An dieser Stelle gibt es immer die jeweils aktuelle Version, die grade läuft.
Edit: Der Code ist jetzt in einem Repository.
ObjFW 0.4-alpha1 released
Created: 03.01.2011 22:16 UTC
Soeben habe ich ObjFW 0.4-alpha1 released. ChangeLog und Download wie immer hier. Ich glaube, es gab noch nie so viele Änderungen in einem Release. Die größten dürften Blocks- und XML-Support sein, sowie die Änderung der Lizenz: ObjFW kann jetzt auch unter den Bedingungen der GPLv2 oder GPLv3 genutzt werden. Und weil es so viele Änderungen gibt, gibt es diesmal auch erst ne Alpha ;).
Keine Blog-Berichterstattung vom 27c3
Created: 28.12.2010 22:48 UTC
Wollte nur eben drauf hinweisen, daß ich diesmal vmtl. nicht vom 27c3 bloggen werde, da das meiste eher kurze Sachen sind, die ich dann twittere. Meinen Twitter-Feed gibt es hier.
Blog neugeschrieben in Objective-C + ObjFW
Created: 25.12.2010 23:53 UTC
So, ich habe jetzt das Blog neugeschrieben, in Objective-C mit ObjFW. Solltet ihr aber nicht viel von sehen, sollte immer noch alles genau so aussehen und sich genau so verhalten wie vorher.
Lediglich beim Atom-Feed werdet ihr einen Unterschied feststellen: Ruby hatte da Murks mit der Zeitzone gemacht. ObjFW macht's richtig und jetzt steht dort die korrekte Zeit. (Ruby hat bei der Änderungszeit der Datei irgendwie die Zeitzone draufaddiert, obwohl es schon in lokaler Zeit war oder sowas.)
Nachtrag: Ok, ich hatte Langeweile und jetzt gibt's doch noch eine Neuerung. Statt der langweiligen ?id=77 URLs kann man jetzt auch einfach ?4D verwenden. Oder ?0x4D. Oder ?x4D. Oder ?$4d. Naja, so langsam sollte klar sein, daß man sie hexadezimal angeben kann ;).
ObjFW Revision 1000
Created: 20.10.2010 18:49 UTC
Wie ich eben beim Committen bemerkt habe, ist Revision 1000 bereits gestern erreicht worden! :) Dann fehlt ja nur noch ein 0.4er Release ;).
WebKeks 2.0
Created: 14.10.2010 16:39 UTC
Wie sicherlich einige von euch gemerkt haben, war der WebKeks in letzter Zeit ziemlich schlecht erreichbar, bis er dann irgendwann garnicht mehr erreichbar war.
Der Grund war, daß die Hardware anfing kaputt zu gehen - nicht weiter verwunderlich, so alt wie die war (PII 450 war das). Also hab ich die Platte und die beiden NICs in einen anderen Rechner gepackt und weiter. Das ging auch anfangs - aber irgendwann hat er dann auch dort angefangen, ständig einzufrieden. Irgendwann hab ich dann rausgefunden, daß es die Festplatte war. Da die Hardware, durch die ich den WebKeks ersetzt hatte, aber sowieso nicht für den Dauerbetrieb dort bleiben konnte, habe ich mir neue Hardware zugelegt: Einen Athlon X2 4450e. Dazu 1 GB RAM und eine 10k RPM SCSI HD, die ich noch rumfliegen hatte.
Das Installieren des neuen Systems war aber garnicht so einfach: Der Kernel ist schon im Installer gecrasht, sowie der die Netzwerkkarte ansprechen wollte. Also NIC im BIOS deaktiviert und installiert. Als das System dann installiert war, hab ich mich rangemacht rauszufinden, warum es crasht: Scheinbar meldet die Karte 31 PHYs - statt 1. Also hab ich mir eben einen kleinen Kernel-Patch geschrieben, der alle außer den ersten PHY ignoriert. Damit läufts jetzt einwandfrei.
Das erste was ich umgezogen hatte war der Mailserver und der Asterisk. Leider ist während des Kopierens der Mails die alte Platte abgeraucht - also mußte dann das Backup vom Vortag her. Danach hab ich dann den Jabber-Server wieder eingerichtet, gefolgt von den Gateways. Bei der Gelegenheit bin ich dann gleich auf Spectrum umgestiegen, der bisher ganz gut läuft.
Und heute hab ich dann endlich wieder den Webserver inkl. des Blogs und Mercurial aufgesetzt. Das war eine ganz schöne Arbeit, weil das ganze in einem chroot läuft und ein ldd einem nicht direkt verrät, welche Libraries man braucht, weil einige Python-Module zur Laufzeit versuchen, .so-Files nachzuladen. Aber jetzt läuft alles :). Und wo ich den Webserver dann auch mal eingerichtet habe, habe ich auch gleich mal den JWChat wieder zum Laufen gebracht.
Sollte irgendwas nicht wie gewohnt funktionieren: Bitte melden!
PS: Dank der neuen Hardware ist jetzt auch alles 64-bittig ;).
ObjFW 0.3.1
Created: 19.06.2010 17:06 UTC
Soeben habe ich ObjFW 0.3.1 released. Es handelt sich dabei um ein reines Bugfix-Release. ChangeLog, Download etc. gibt es wie immer hier.
Wireless-Audiokabel via Soundflower, esdrec/esdcat + PulseAudio
Created: 08.06.2010 19:16 UTC
Ich habe endlich einen guten Ersatz für mein 20 Meter Audiokabel gefunden. Auf meinem Desktop läuft einfach PulseAudio, auf dem Laptop (OS X) habe ich einfach Soundflower und esound installiert. Soundflower ist eine virtuelle Soundkarte, die alles, was sie ausgibt, wieder in den Input gibt. In OS X stellt man dann einfach die Soundkarte auf Soundflower um (für Ausgabe und Aufnahme!), startet esd und verwendet dann esdrec | esdcat -s host. Funktioniert hier prima über WLAN (802.11g) für Musik, zumal man einzelne Anwendungen auch noch zusätzlich auf die Notebook-Soundkarte legen kann :). Man hat also quasi eine weitere Soundkarte, die alles remote abspielt. Das ganze sollte mit jedem bliebigen OS als Client funktionieren, das esound kann.
Nachtrag: Eigentlich bietet sich das EFIKA, das ich hier noch rumfliegen habe, ja perfekt als Server dafür an. Es hat einen digitalen Audioausgang, mit 400 MHz wirklich genug Power für den Job und einen maximalen Stromverbrauch von 4.1 W :).
Update: Mit neueren esound + OS X versionen ist es nötig, esd(rec) einen Host anzugeben. Hierzu wird esd dann mit esd -tcp -bind ::1 gestartet und statt esdrec einfach esdrec -s ::1 verwendet.
Warum VP8 nicht die Lösung ist
Created: 20.05.2010 10:48 UTC
Immer mehr Seiten berichten darüber, daß mit VP8 endlich ein freier, offener und patent-freier Codec existieren würde und wir alle damit vor der MPEG-LA gerettet wären. Was in dem ganzen Hype aber wohl untergeht ist, daß bei VP8 nicht nur die Gefahr von U-Boot-Patenten besteht, sondern noch eine weitaus größere: VP8 ist im Großen und Ganzen ein Rip-Off von H.264.
Theora wurde immer wieder mit der Gefahr von U-Boot-Patenten abgewiesen. Die selben Firmen, die sich bei Theora über die möglichen Gefahren von U-Boot-Patenten (welche bei Theora aller Wahrscheinlichkeit nach FUD sind, da immer noch niemand konkrete Patente vorzuzeigen hatte) Sorgen machen, kündigen aber jetzt an, VP8 zu implementieren. VP8 aber verwendet zu 90% die selben Techniken wie das H.264 Baseline Profile. Somit kann man ziemlich sicher davon ausgehen, daß die MPEG-LA mindestens ein Patent besitzt, von dem VP8 betroffen ist. Sowie die MPEG-LA auch nur ein Patent hält, kann sie die selben Lizenzbedingungen stellen wie bei H.264. Man hätte damit also nichts gewonnen. Und dies dürfte mitunter auch der Grund sein, warum Firmen, die bei Theora Angst vor U-Boot-Patenten hatten, jetzt auf VP8 setzen: Diese Firmen haben alle eine Lizenz für H.264. Somit dürfen sie auch die H.264-Patente einsetzen. Angst vor Patenten die von anderen als der MPEG-LA gehalten werden brauchen sie nicht haben, da so gut wie jeder, der irgendwelche Patente in Sachen Video-Kompression hat, diese in den Pool der MPEG-LA gegeben hat, um andere Patente der MPEG-LA nutzen zu können. Diese Firmen implementieren also jetzt VP8, damit alle, die sich über H.264 beschwert haben, Ruhe geben, in der Hoffnung, daß die nicht bemerken, daß die Situation die selbe wie mit H.264 ist - und diese Strategie scheint ja leider auch noch aufzugehen.
IMO gibt es auch noch eine weitere Gefahr: VP8 ist ganz im Sinne der MPEG-LA. Sie hält definitiv mindestens ein Patent an VP8, aber die gesamte OpenSource-Szene konzentriert sich jetzt auf VP8, statt an Theora weiterzuarbeiten. Die MPEG-LA konnte bis heute kein Patent vorzeigen, das Theora ernsthaft bedroht. Ich bin mir ziemlich sicher, daß sie es bei VP8 können werden. Und ich bin mir auch ziemlich sicher, daß sie damit warten werden, bis alle VP8 verwenden. Denn dann haben wir wieder genau die selbe Situation wie jetzt: Totale Abhängigkeit von der MPEG-LA. Bloß daß Theora dann noch weniger eine Alternative ist als heute, da Theora noch weniger Manpower bekommt.
Google weigert sich leider auch, an VP8 noch irgendwelche Änderungen vorzunehmen, sodaß das Argument „Man kann es ja noch so verändern, daß man die patentierten Teile austauscht“ nicht funktioniert. Google tut das, weil sie die aktuelle Implementierung quasi als Standard definiert haben - und bereits die ersten Hardware-Umsetzungen als Prototypen existieren. Und es sind bereits Bugs im offiziellen Decoder und Encoder gefunden worden, die somit in die Spec übertragen wurden. Aber um die Kompatibilität nicht zu brechen, will Google diese nicht fixen.
Daher ist das einzig sinnvolle, was man jetzt machen könnte, VP8 zu forken, einen Patentanwalt damit beauftragen, festzustellen, welche Teile wirklich patentiert sind und dann diese zu ersetzen. Aber alles andere wird uns weiter in die Abhängigkeit von der MPEG-LA treiben…
Update: Für die, die mit dem Problem mit der MPEG-LA nicht vertraut sind: Lest euch mal diesen Link durch.
ObjFW 0.3
Created: 09.05.2010 15:00 UTC
Ich habe soeben ObjFW 0.3 released. Diesmal gibt es eine wirklich große Anzahl an Neuerungen, am besten guckt ihr euch das ChangeLog an.
Den Download gibt es wie immer hier.
ObjFW-Bridge
Created: 01.04.2010 21:44 UTC
Ich habe eben mal ObjFW-Bridge in ein Repo gepackt. Damit ist es möglich, ObjFW-Objekte in Cocoa-/OpenStep-Objekte und umgekehrt zu konvertieren. Das Repo findet ihr hier.
ObjC-Runtime
Created: 25.03.2010 19:36 UTC
Wie ich ja schon vor ein paar Tagen geschrieben hatte, habe ich mal mit einer ObjC-Runtime angefangen. Nun, ich hab sie heute mal soweit gebracht, daß man sie veröffentlichen kann und in ein Repo gepackt. Sie ist jetzt schon ca. doppelt so schnell wie die GNU libobjc, selbst wenn man die Assembly-Optimierungen mit -DNO_ASM ausschaltet. Allerdings fehlen noch Exceptions, Protocols und Threading. Wobei letzteres recht einfach sein sollte, da z.B. die Dispatch-Table bereits eine Datenstruktur hat, die keine Locks benötigt.
Apple-Tastatur
Created: 22.03.2010 20:21 UTC
So, da mein Vater sich ein 17" MacBook Pro auf eBay gekauft hat und der Verkäufer noch eine Tastatur beigelegt hat, weil das MBP eine US-Tastatur hat, habe ich jetzt eine Apple-Tastatur, da mein Vater sie nicht wollte. Und was stelle ich erstmal unter Linux fest? die ^ und <>-Taste sind vertauscht - vom Keycode her. Mich stört das besonders, weil ich ja das US-Layout habe und dort die <>-Taste für Sonderzeichen verwende. Auch sind Alt und Cmd genau vertauscht im Vergleich zu einer gewöhnlichen Tastatur (Cmd ist dort die Windows-Taste).
All das hat mich doch direkt genervt, daher habe ich mal eine .Xmodmap geschrieben. Falls jemand von euch noch das selbe Problem hat: Ihr findet sie hier (dotXmodmap-apple). Ist zum nach dem Laden der eigentlichen .Xmodmap gedacht.
Ansonsten muß ich sagen, daß sie sich echt gut tippt. Der Abstand zwischen den Tasten hat mich zwar erst was genervt, aber nach grade mal 5 Minuten hat man sich schon dran gewöhnt und merkt dann, daß man dadurch deutlich weniger Tippfehler macht.
Nachtrag: Mit folgendem Trick kriegt man dann auch die F-Tasten so hin, wie man das gerne hätte (am besten in die /etc/rc.local schreiben):
echo 2 >/sys/module/hid_apple/parameters/fnmode
Ist irgendwie deutlich sinnvoller unter Linux, da außer den Lautstärke- und Vor-/Zurück-Tasten eh nichts wirklich klappt. Da hat man von den F-Tasten doch deutlich mehr, die werden ja unter Linux im Gegensatz zu MacOS X genutzt.
Jenkins' Hash
Created: 19.03.2010 21:18 UTC
Ich schreibe grade aus Langeweile meine eigene ObjC-Runtime (und sie funktioniert auch schon) und habe daher mal ein paar Benchmarks gemacht in Sachen Hashtables, Hashfunktionen, Sondierung und Größen und dabei eine interessante Entdeckung gemacht: Normalerweise geht man ja davon aus, daß man am besten als Größe für die Hashtable eine Primzahl nimmt und dann den Hash modulo der Größe nimmt, um so möglichst wenig Kollisionen zu bekommen. Nun, bei Jenkins' Hash verhält es sich anders: Eine Power of 2 als Größe nehmen und den Hash mit (Größe - 1) zu ANDen ergibt deutlich weniger Kollisionen. Also wenn ihr Jenkins' Hash nehmt (der übrigens wegen seines Avalanche-Verhaltens sehr gut für Hashtables ist): Macht euch garnicht die Mühe, nur Primzahlen als Größe zu nehmen und dann Modulo zu verwenden. Power of 2 und dann mit (Größe - 1) ANDen geht nicht nur schneller, sondern erzeugt auch noch weniger Kollisionen.
ObjFW 0.2.1
Created: 14.03.2010 13:29 UTC
So, ich habe dann eben endlich mal 0.2.1 released, nachdem das so lange auf meiner TODO stand und eigentlich soweit auch fertig war.
Das ChangeLog gibt es wie immer hier und den Download hier.
Migration von ejabberd zu Prosody
Created: 14.03.2010 13:22 UTC
Ich habe - wie einige von euch bestimmt mitbekommen haben - vor ein paar Tagen den Jabber-Server von ejabberd zu Prosody migriert und ich muß echt sagen: Ich bin begeistert, der Geschwindigkeitsunterschied ist echt enorm! Und das, obwohl Prosody in Lua geschrieben ist und kein RDBMS nutzt! Da fragt man sich echt, wie viel die ejabberd-Entwickler da falsch gemacht haben müssen, daß Prosody in ein paar Sekunden schafft, wofür ejabberd Minuten gebraucht hat…
Auch nett an Prosody ist der MUC-Support: Da kann man nämlich von mehreren Resourcen mit dem selben Nick in einen MUC, das ist echt praktisch :).
iPhone und die Kopfhörerlautstärke
Created: 23.02.2010 22:37 UTC
Da ich gestern krankheitsbedingt immer noch die Ohren etwas zu hatte und es mich im Bus genervt hat, daß die maximale Lautstärke beim iPhone doch recht gering ist und es mich auch schon immer nervte, daß insbesondere einige nicht-Apple-Kopfhörer viel zu leise sind, habe ich mich mal auf die Suche begeben. Ich hatte ja von Anfang an vermutet, daß es an irgendwelchen EU-Bestimmungen liegt, denn das iPhone aus den USA war deutlich lauter. In Cydia habe ich zwar 3 verschiedene Volume Boosts gefunden, die aber alle keinen Unterschied brachten.
Nun, die Vermutung mit den EU-Bestimmungen war richtig, wie folgende Datei dann bewiesen hat:
/System/Library/PrivateFrameworks/Celestial.framework/RegionalVolumeLimits.plist
Ich habe die Datei einfach mal auf meinen Laptop kopiert und dort im plist-Editor geöffnet. Dort war dann eine Liste mit Ländern und deren maximaler Lautstärke. Nachdem ich einfach alle Einträge entfernt habe, die Datei wieder auf das iPhone geladen habe und das iPhone neugestartet habe, war der Kopfhörer gleich deutlich lauter. Jetzt kann ich auch problemlos den Sony-Kopfhörer nutzen, der was leiser ist als der von Apple ;).
Ach ja, ich rate davon ab, nach dem Reboot direkt mit voller Lautstärke zu probieren - bei den Apple Kopfhörern bläst einem das echt die Ohren weg ;).
Nimbuzz & Spam, die 2.
Created: 07.02.2010 14:44 UTC
Wollte nur mal eben mitteilen, daß ich noch ein paar Spam-Mails an die e-mail-Adressen bekommen habe, die nur Nimbuzz kennt (scheinbar hatte ich einen Typo in der REJECT-Regel). Der Absender war übrigens wieder auf Facebook geforged. Also da ist definitiv wohl jemandem ne Datenbank geleaked (wenn ihr dort Accounts habt / hattet und evtl. sogar noch andere Protkolle wie ICQ darüber genutzt habt, dann solltet ihr evtl. mal euer Passwort ändern) oder was weiterverkauft worden…
So, ich fix jetzt erstmal die REJECT-Regel…
Nimbuzz gibt e-mail-Adressen an Spammer
Created: 04.02.2010 16:44 UTC
Wie sicherlich einige von euch wissen, verwende ich für jeden Service eine eigene e-mail-Adresse und die verwende ich dann ausschließlich dort. Nun, ich habe bei Nimbuzz 2 Accounts, einmal einen zum Testen und einmal einen für die iPhone-Anwendung. Und was seh ich eben in meiner Inbox? 2 Spam-Mails, die vorgeben, von Facebook zu sein und die berühmten blauen Pillen bewerben und an die ausschließlich Nimbuzz bekannten e-mail-Adressen gingen. Ich hatte für beide Accounts verschiedene e-mail-Adressen und an beide ging diese Spam-Mail. Was sagt uns das? Nimbuzz ist nicht nur eine Datenkrake, sondern verkauft auch noch entweder e-mail-Adressen an Spammer oder wurde geowned. Jedenfalls bestätigt das meine Meinung, von Nimbuzz Abstand zu halten. Wer schon meint, die Rechte an allen darüber übertragenen Nachrichten zu haben, der gibt eben auch e-mail-Adressen an Spammer weiter (ob freiwillig oder unfreiwillig da geowned weiß wohl nur Nimbuzz). Jedenfalls haben grade 2 e-mail-Adressen eine neue REJECT-Regel bekommen…
ObjFW 0.2
Created: 01.02.2010 18:27 UTC
Soeben habe ich ObjFW 0.2 released. Die größte Änderung dürfte der vollständige ObjC 2-Support sein, sogar unter Linux, Windows und anderen nicht-Apple-Systemen.
Daneben gibt es aber auch eine Menge andere Änderungen, daher empfehle ich euch, das ChangeLog zu lesen.
Den Download und die Dokumentation gibt es wie immer hier.
Vortrag über Zensur
Created: 21.01.2010 15:13 UTC
Ich wollte nur mal eben mitteilen, daß Alvar Freude heute an der RWTH einen Vortag über Zensur im Fo3 hält. Wer also grade in Aachen oder Umgebung ist: Vorbeischauen! :)
ObjFW 0.1.2
Created: 15.01.2010 13:10 UTC
So, ich habe soeben ObjFW 0.1.2 released. Es enthält nur 2 kleine Verbesserungen, einmal wurde ein Bug in -[removeObject:] und -[removeObjectIdenticalTo:] in OFMutableArray behoben, der dazu führen konnte, daß nicht alle Objekte richtig entfernt wurden und es evtl. einen Out-of-Bounds-Lesezugriff gab. Die andere Verbesserung ist eigentlich garkeine Erwähnung wert: In der plist des Frameworks wurde die URL vom Repository auf die Homepage geändert. Den Download und das ChangeLog gibt es hier.
ObjFW 0.2 kommt übrigens auch bald ;).
ObjFW und Properties
Created: 05.01.2010 23:35 UTC
So, ObjFW unterstützt jetzt auch Properties auf Nicht-Apple-Systemen. Damit ist es mit ObjFW möglich, ObjC 2 vollständig auch unter Linux, Windows etc. zu nutzen (clang vorrausgesetzt). ObjFW rüstet dafür die in der GNU Runtime fehlenden Sachen nach. Die Dot-Notation stellt keine Anforderungen an die Runtime, sodaß dies schon immer ging und damit der ObjC 2-Support in ObjFW vollständig ist.
Ob ObjC 2-Support alleine schon ein neues Release wert ist, habe ich noch nicht entschieden. Aber das nächste Release wird ObjC 2-Support definitiv mitbringen, jedoch auch mit einem ObjC 1-Compiler compilierbar sein. D.h. ObjC 2 wird angeboten, aber niemand gezwungen, es zu nutzen. Nutzer von ObjFW können selber entscheiden, ob ihr Projekt ObjC 2 nutzt und damit Leute ohne einen ObjC 2-Compiler ausschließt oder nicht.
ObjFW 0.1.1
Created: 04.01.2010 14:57 UTC
So, ich habe soeben ObjFW 0.1.1 released. Es hat nur ein paar kleine Änderungen, hauptsächlich kleine Bugfixes. Aber da 0.2 jetzt schon eine leicht abweichende API hat (keine Sorge, nichts, was wirklich der Rede wert wäre) und ich noch nicht weiß, wann 0.2 rauskommen wird, habe ich mich entschlossen, ein paar Fixes und kleine Verbesserungen backzuporten.
Was genau ich geändert habe guckt ihr am besten im ChangeLog nach, den Download gibt's hier.
Fast Enumerations
Created: 03.01.2010 21:24 UTC
So, ich hab heute mal Fast Enumerations in ObjFW implementiert. Das ganze läuft auch mit clang unter Nicht-Apple-Systemen ohne Probleme und wird dann im 0.2er-Release drin sein. Ich gehe davon aus, daß in 0.2 dann wohl kompletter ObjC 2.0-Support sein wird. Es ist übrigens rein optional, sodaß man ObjFW auch nach wie vor mit gcc bauen kann. Man kann sogar ObjFW mit gcc bauen und hat nachher Support für Fast Enumerations drin, kann sie aber eben nicht in seinen Anwendungen nutzen, wenn man die mit gcc baut.
Natürlich kann ich mir ein Beispiel, wie viel schöner doch einiges mit Fast Enumerations ist, nicht verkneifen ;). Daher hier erstmal, wie man es ohne Fast Enumerations machen würde:
id *objs = [array cArray];
size_t count = [array count];
for (i = 0; i < count; i++)
[objs[i] foo];
Und so viel schöner sieht das ganze dann mit Fast Enumerations aus:
for (id obj in array)
[obj foo];
Deutlich schöner, oder? Und von so Sachen wie in ner Schleife -[objectAtIndex:] nutzen will ich garnicht erst reden - das ist nicht nur hässlich, sondern auch noch lahm, aber wurde früher von Cocoa-Programmierern oft gemacht. Mit Fast Enumerations steht also jetzt was zur Verfügung, das schnell und schön ist :).
Es wäre übrigens gut, wenn ein paar Leute einfach mal die neuste Version aus dem Mercurial-Repository auschecken könnten und damit rumspielen würden :). In 0.1 sind mir nämlich ein paar Bugs aufgefallen (fehlendes retain + autorelease, falscher Range Check), die leider niemand reported hat, sowas will ich bei 0.2 verhindern (daher kommt die Tage auch ein 0.1.1)…
Das unerträgliche Gefaile der Deutschen Bahn
Created: 31.12.2009 11:28 UTC
Ich kenne echt niemanden, der so unerträglich failed wie die Bahn. Erst sagt man mir, der Zug von Berlin Friedrichstraße nach Berlin Schönefeld käme 20 Minuten später. Dachte ich na gut, das könnte noch klappen. Auf meine Frage hin, ob es nicht Sinn machen würde, die S-Bahn statt den RE zu nehmen (es stand wenigstens jemand am Gleis!), hieß es „Nein, es sind ja nur 20 Minuten, das geht so schneller“. Da ich Angst hatte, den Flug zu verpassen, wollte ich dann lieber ein Taxi nehmen, aber der Taxifahrer war so ehrlich mir zu sagen, daß er 50 Minuten brauchen würde, was dann doch sehr knapp gewesen wäre. Also wieder auf den Zug warten. Zur Sicherheit habe ich bei German Wings mal angerufen, bis wann ich noch einchecken kann - bis 11:14 hätte das geklapt und der Zug wäre mit 20 Minuten Verspätung um 11:00 in Berlin Schönefeld angekommen. Als die 20 Minuten dann um waren, hieß es nur lapidar, der Zug würde ausfallen und der nächste um 11:36 ankommen (Abflug war um 11:45 - um 10:10 hätte er Friedrichstraße losfahren müssen). Das ging also nicht mehr, und Taxi war jetzt auch schon zu spät. Grandios, der Flug war weg und das, obwohl ich extra mehr als rechtzeitig los bin. Danke, Deutsche Bahn!
Aber damit noch nicht genug! „Auf zum Hauptbahnhof und den nächsten ICE nehmen“, dachte ich. Also geh ich zum Service Point und laß mir einen ICE raussuchen - toll, der ICE wurde durch einen IC ersetzt (naja, wenigstens hat er Strom!). Aber man sagt mir, ich bekäme die Fahrt erstattet und gab mir eine Bestätigung, daß der Zug ausfiel. Also alles halb so wild, dachte ich. Aber die Betonung liegt auf dachte! Als ich dann das Ticket gelöst hatte (102€! Ich hatte für den Flug hin und zurück grade mal 140€ bezahlt!) und im Zug sitze, erfahre ich dann, daß ich falsch informiert wurde (wie immer, juhu!): Ich bekomme nur die Fahrt, die ich nach Berlin Schönefeld bezahlt hätte, erstattet! Super! 1.50€ krieg ich! Grandios!
Aber damit immer noch nicht genug! Kaum sitz ich im Zug, erfahre ich, daß um 15:00 auch noch ein Flug für 60€ gegangen wäre. Und ich habe jetzt 102€ bezahlt! Na super!
Die Bahn ist einfach das beschissenste Unternehmen, das es gibt. So failen kann kein anderer. Ein "EPIC FAIL" wäre da eine gnadenlose Untertreibung. Da fliegt man extra, damit einem so eine Scheiße erspart bleibt, aber die Bahn findet doch immer wieder Wege dafür zu sorgen, daß man erst 5 Stunden später ankommt… und ihnen auch noch Geld für ihr Gefaile zahlen muß!
Naja, jedenfalls war ich gestern noch im C-Base und es war ziemlich nett. An Getränken mußte ich nichts zahlen, weil ich erstmal schon an der Kasse Bons für Getränke gekriegt habe, weil ich Engel war und dann direkt danach noch vom CCC als Dankeschön fürs Engeln Bons gekriegt habe. :)
So, ich sitz dann mal im Zug und freu mich weiter über den tollen Netzausbau von E-Plus…</sarcasm>
Nachtrag: Das macht doch richtig Spaß:
PING 8.8.8.8 (8.8.8.8): 56rdata bytes
64 bytes from 8.8.8.8: icmp_seq=0 ttl=238 time=27193.328 ms
64 bytes from 8.8.8.8: icmp_seq=1 ttl=238 time=26114.893 ms
64 bytes from 8.8.8.8: icmp_seq=5 ttl=238 time=22374.941 ms
64 bytes from 8.8.8.8: icmp_seq=6 ttl=238 time=21337.998 ms
Sofern man überhaupt Internet hat und das iPhone nicht nur „Suchen…“ meldet…
Nachtrag 2: Und der Zug hat jetzt schon 18 Minuten Verspätung! Juhu! Das wird sich bestimmt noch im Verlaufe der Fahrt zu über einer Stunde aufsummieren! Mindestens!
Nachtrag 3: Neuer Rekord:
64 bytes from 8.8.8.8: icmp_seq=195 ttl=238 time=57296.914 ms
64 bytes from 8.8.8.8: icmp_seq=196 ttl=238 time=57200.185 ms
# Aber 90% der Zeit habe ich überhaupt kein Internet…
Nachtrag 4: E-Plus ist auch ein EPIC FAIL. 90% der Strecke nichtmal Netz zum Telephonieren da. Ab und zu mal n paar Sekunden Netz, das wars dann - halt genau dann, wenn man an nem Bahnhof ist. O2 ist auch nicht viel besser. Werde wohl wohl oder übel zu T-Offline oder Zensurfone wechseln müssen. :(
Nachtrag 5: 50 Minuten Verspätung wurden es! Und dafür hab ich dann 102€ bezahlt! Boah, ärgere ich mich grade über diese Fehlinformation, daß ich die Fahrt erstattet kriegen würde. Hätten die das nicht gesagt, wär ich für 60€ geflogen! Grrr…
26c3, Day 4
Created: 30.12.2009 14:22 UTC
Irgendwie komme ich diesen Congress garnicht zum Bloggen. Das liegt einerseits daran, daß ich oft zwangsweise die ganze Nacht durchmache (ganz einfach weil es nicht anders geht) und dann am nächsten Tag garkeine Lust habe zu bloggen, andererseits aber auch daran, daß sich ständig Leute im Engelsystem eintragen und dann nicht erscheinen, sodaß man oft einspringen muß und dann 4 Leute dort fehlen und man Streß pur hat, Leute aufzutreiben, damit der Vortrag überhaupt aufgezeichnet wird.
In Vorträge kommt man meistens garnicht mehr rein, es sei denn, man setzt sich schon einen Vortrag früher rein, das ist echt unzufriedenstellend. Das bcc ist einfach viel zu klein für so viele Leute. Und dieses Jahr war ja auch alles so schnell ausverkauft wie noch nie.
Naja, ich empfehle euch, euch nachher einfach mal die Videos anzugucken.
Im Hackcenter war ich kaum, da es einfach immer viel zu voll war. Produktiv habe ich auch nicht wirklich was gemacht, was auch daran liegen dürfte, daß ich kaum im Hackcenter war.
Das WLAN war teilweise sehr gut, teilweise aber auch unnutzbar und im Engelraum gab es das GSM-Netz nicht, sonst aber überall. Und draußen liegt grade Schnee ;). Hoffentlich gibt das keine Probleme mit dem Flieger morgen…
26c3, Day 3, Part 1/$unknown
Created: 29.12.2009 14:18 UTC
So, am 1. Tag und den ganzen 2. Tag bin ich nicht mehr zum Bloggen gekommen. Gestern war ich einfach viel zu müde noch irgendwas zu tun, heute hat der Tag dann direkt mit Videoengelei begonnen.
Talks habe ich leider deutlich weniger gesehen, als ich wollte. Das werde ich dann wohl zu Hause nachholen müssen. Aber erdgeists und fefes Vortrag über die Major API Fuckups war recht gut - zumal ich mich mit fast jedem der dort erwähnten Fuckups schon rumärgern durfte.
Mir fällt grade ein, daß ich noch nichtmal dazu gekommen bin, meine DECT zu bloggen. Die ist ganz Jabber-typisch: 5269. Also wenn während des Congresses irgendwas ist, könnt ihr mich dort erreichen (siehe 26c3 Wiki für Dial-In).
So, dann hoffe ich mal, daß ich jetzt mehr zum Bloggen komme.
26c3, Day 1, Part 1/$unknown
Created: 27.12.2009 10:31 UTC
So, ich sitze (ja, sitze sogar! *g*) grade im Saal 1 bei der Keynote. Ich bin gestern garnicht zum Bloggen gekommen, dabei bin ich schon seit dem 25. abends in Berlin. Die Schlange gestern war einfach unerträglich lang, ging 2x durchs ganze bcc. Ich Idiot mußte ja auch vergessen, das Geld fürs Presale-Ticket zu überweisen. Naja, jedenfalls habe ich meins seit gestern abend. Und die Keynote hat noch nichtmal angefangen, da sind schon alle ausverkauft (nur noch Day-Tickets).
Das Programm sieht dieses Jahr wieder sehr interessant aus, dummerweise muß man sich oft teilen, um alles, was man sehen will, zu sehen ;). Und leider habe ich mich auch viel zu spät im Engelsystem für die Shifts eingetragen, sodaß ich bei vielen Vorträgen, wo ich es gerne machen würde, keinen Video-Engel machen kann.
So, die Keynote geht jetzt los, weitere Blogs gibts später.
Weihnachtsgeschenk
Created: 24.12.2009 09:34 UTC
So, von mir gibt es ein Weihnachtsgeschenk für euch alle ;). Und zwar habe ich heute ObjFW 0.1 released. Weitere Informationen gibt es hier!
Vorgezogenes Weihnachtsgeschenk von NVidia
Created: 04.12.2009 12:24 UTC
NVidia hat bereits jetzt sein Weihnachtsgeschenk verteilt: FreeBSD-Treiber für AMD64! Und damit noch nicht genug: Sogar 32-bit Linux ABI Compatibility Libraries! D.h. damit laufen sogar 32-bit Linux Anwendungen beschleunigt mit GLX (was ja z.B. unter Solaris nicht der Fall ist)!
Ich werd dann demnächst mal auf meiner freien primären Partition mit FreeBSD 8 rumspielen und wenn es wirklich so gut läuft, wie es sich da liest, endlich ein BSD zu meinem Hauptsystem machen können.
libobjfw → ObjFW
Created: 10.11.2009 16:15 UTC
Nein, keine Sorge, libobjfw ist nicht tot ;). Die Repository-URL hat sich nur geändert und lautet jetzt https://webkeks.org/hg/objfw/ (alle alten URLs im Blog wurden auch aktualisiert).
Die URL wurde gewechselt, da ich mich entschieden habe, libobjfw in ObjFW umzunennen. Erstens ist der Name kürzer und zweitens paßt es so deutlich besser, wenn man das ganze als Mac OS X / iPhone Framework baut (da hat man gewöhnlich kein lib im Namen). libobjfw war also nicht mehr passend, da man es jetzt nicht mehr nur als Library bauen kann, sondern eben auch als Mac OS X / iPhone Framework.
Apropos iPhone: Ich konnte ObjFW das letzte mal unter 2.2.1 testen, weil das SDK seit 3.0 nicht mehr auf PPC läuft und der Compiler direkt auf dem iPhone seit 3.0 auch kaputt ist. Seit gestern habe ich aber eine selbstgebaute Toolchain für Leopard/PPC und Linux/x86 für iPhone OS 3.1.2 und kann somit wieder für das iPhone compilieren. Und ObjFW lief auf Anhieb unter 3.1.2 ;).
Apple Fanboy? Nö.
Created: 24.09.2009 14:27 UTC
Es kursiert ja öfter mal das Gerücht, ich sei ein Apple Fanboy. Aber dem kann ich eigentlich nur widersprechen. Genauer gesagt stört mich doch so einiges an Apple und finde mehr zum Kotzen als ich gut finde. Klar, ich hab 2 Apple Produkte, ein PowerBook und ein iPhone, aber das hat beides ganz andere Gründe, als daß es von Apple ist. Ich werde hier erst mal die Vorteile der beiden auflisten und dann, was mich so sehr an Apple stört.
Das PowerBook habe ich mir nur gekauft, weil es schön klein ist (12", damals gabs noch keine Netbooks in ner anständigen Größe) und - das war der Hauptgrund - weil es eine PowerPC-CPU hat. Da werden sich jetzt die meisten fragen, warum man denn einen PowerPC möchte, der sei doch alt und lahm. Aber für mich reichts und ich finde die Intel-Architektur einfach zum kotzen - und ich weiß, wovon ich rede, ich hab genug x86 Assembly gemacht, inklusive Bootloader und einem winzigen Kernel. Und mit AMD64 wurde es nicht besser, da hat man jetzt auch noch eine ganz bescheuerte ABI. Ich bin halt Geek, ich brauch mein Spielzeug ;). Und was gibt es sonst an nicht-x86 Notebooks in 12"?
Das 1. iPhone hatte ich ja nichtmal selbst gekauft, das hatte ich bekommen, um eine Anwendung darauf zu portieren. Ich wollte damals eigentlich kein iPhone und konnte es zuerst auch nicht leiden. Das hat sich dann aber geändert, als ich gemerkt habe, wie viel man damit eigentlich machen kann, sofern man denn den Jailbreak hat. Auf dem iPhone selber compilieren, alles in Objective-C geschrieben, etc. - das waren schon deutliche Vorteile für mich. Zumal man durch die Objective-C Runtime ja auch zur Laufzeit sehr viel an bereits fertigen Programmen, zu denen man keinen Source hat, ändern kann. Und das alles hat mich dann im Endeffekt doch dazu gebracht, mir dann ein 3G selber zu kaufen, denn die Konkurrenz hat doch noch erhebliche Probleme IMO: Android ist mir viel zu Google-zentriert und man muß für fast alles Google-Dienste nehmen und die Bedienung war ein wenig inkonsistent, als ich mal eins zum Probieren in der Hand hatte. Und naja, Symbian fällt eh raus, das kann ich überhaupt nicht leiden. Usability Hell. Man muß sich schon echt anstrengen, etwas so umständlich zu bedienen zu machen. Und WebOS mit dem Palm Pre ist auch was sehr limitiert. Und die Limitierungen des iPhone (z.B. kein Multitasking) lassen sich ja alle mit einem Jailbreak umgehen. Klar, ohne Jailbreak wäre das iPhone nicht wirklich nutzbar. Aber mit ist es sehr gut nutzbar.
Das alles sind aber noch lange keine Gründe, Apple gut zu finden. Da gibt es direkt mehrere Sachen, die einem übel aufstoßen:
Da wäre einmal der Punkt, wie Apple mit ihren PowerPC-Kunden umgeht. Die werden einfach mal abgesägt. Und die Core1 Rechner werden die nächsten sein. Apple zwingt Kunden zum Kauf neuer Hardware durch Droppen von Support für alte - und das, obwohl die Hardware leistungsmäßig noch auf der Zeit ist. Mir kann niemand erzählen, ein Quad G5 sei so langsam, daß man den nicht mehr gut benutzen könnte. Klar, Apple wollte die Objective-C 1 ABI loswerden, da es die Objective-C 2 ABI ermöglicht, ivars auch noch nachträglich hinzuzufügen, ohne die Binärkompatibilität zu brechen. Um die neue Runtime zu haben, ohne alle existierenden Anwendungen zu brechen, hat Apple daher bei PPC32 und x86 die Objective-C 2 Runtime mit der Objective-C 1 ABI genommen. PPC64 und x86_64 hatten von Anfang an die neue Runtime und ABI. Verständlich, daß sie die Objective-C 1 ABI loswerden wollen, damit sie in Zukunft ihre Libs einfacher aktualisieren können. Aber: Dann hätten sie auch x86 droppen müssen und nicht nur PPC32. Und PPC64 hatte ja eh von Anfang an die neue Runtime und die neue ABI. Es gab also keinen technischen Grund, PPC64 zu droppen. Von daher ist abzusehen: Als nächstes fliegt x86. Also, an alle, die einen Core1 haben: Ihr könnt schonmal für neue Hardware sparen. Und Apple hätte auch einfach sagen können, daß alte Programme eben mal neu compiliert werden müssen, damit sie noch unter Snow Leopard auf PPC32 laufen, dann hätten sie da auch die neue ABI nehmen können. Aber nein, x86 lassen sie, mit der alten ABI…
Der nächste Punkt wäre natürlich das DRM. Überall ist irgendwo DRM bei Apple, Formate sind undokumentiert, patentiert, etc. Apple versucht alles so geschlossen wie möglich zu halten. Und das kotzt ziemlich an. Es wird eh wieder gebrochen, da könnte man es auch allen leichter machen und es gleich lassen. Welche Nachteil hat Apple bitte, wenn jemand einen Jailbreak macht? Sie haben nicht den geringsten. Im Gegenteil. Das iPhone wurde deutlich populärer dadurch. IMO könnten sie das Jail sogar opt-out machen. Was würde es Apple schaden? Einen Jailbreak kann man eh machen und das wird sich auch nie ändern, egal wie viele Löcher Apple stopft, irgendwer findet ein neues. Und wenn es offiziell mit opt-out geht, dann braucht Apple auch keine Angst haben, daß durch einen Jailbreak unerwartetes Verhalten passiert, weil etwas nicht richtig gemacht ist. Also können sie es auch gleich lassen mit dem ständigen Versuchen, den Jailbreak unmöglich zu machen. Abgesehen davon interessiert sie das bei der Garantie z.B. auch nicht, ob ein Jailbreak gemacht wurde oder was mit dem Vertrag mit dem Carrier ist - also könnten sie es auch gleich offiziell machen.
Naja, und dann bleibt halt zuletzt noch die Sicherheit. Mit der nimmt Apple es echt nicht so genau. Ich denke, da achtet sogar Microsoft mehr drauf. Die OpenSource-Komponenten von OS X werden so gut wie nie geupdated. Die haben dann schonmal ein Jahr lang irgendwelche Bugs, die Remote Code Execution erlauben. Und in der Apple-Software sind dann teilweise auch dicke Bugs, die teilweise echt in die Kategorie „Anfängerfehler“ gehören - aber die leistet sich heutzutage ja jedes größere Unternehmen, scheint ja in Mode zu sein.
Naja, alles in allem sieht man glaube ich, daß mich mehr Sachen stören, als ich wirklich gut finde. Verstehe daher nicht, wie einige drauf kommen, ich sei ein Apple-Fanboy ;).
Apple Garantie++
Created: 06.09.2009 13:55 UTC
Da mein iPhone letztens kaputt gegangen ist und es auch keine Garantie mehr hatte und es auch keinen Sinn macht, noch in ein 1st Gen iPhone zu investieren, habe ich mir ein defektes iPhone 3G auf eBay mit Original-Rechnung gekauft. Bei dem ging lediglich der Touchscreen nicht mehr, alles andere ging. Also erstmal restored, als es hier ankam (es war wohl vorher gejailbreaked). Ich hatte vorher extra beim Gravis Store Aachen angerufen, ob das denn keine Probleme gibt, wenn der Original-Besitzer von dem, der es jetzt hat, abweicht. Das wurde mir am Telephon ausdrücklich bestätigt, daß das überhaupt kein Problem sei.
Als ich es dann dort in Garantie geben wollte, wollten sie sogar einen Beweis haben, daß ich einen laufenden T-Mobile-Vertrag hätte, denn ich wolle es ja sonst eh nur jailbreaken! Und man meinte sogar, es läge nicht an ihnen, sondern Apple würde bei jedem iPhone die IMEI-Nummer nachgucken und anschließend gucken, ob es noch einen laufenden Telekom-Vertrag dazu gibt - was eine glatte Lüge war, wie sich später am Telephon mit der Apple Hotline rausstellte: Apple interessiert der Vertrag nicht im geringsten. Ich tippe ja nach wie vor darauf, daß die von der Telekom war - die kam nämlich auch erst, als ich an dem iPhone, das dort zu Demo-Zwecken ausgestellt war, rumgespielt habe. Die kam mir auch direkt gleich in der Telekom-Art an und sah aus, als ob sie einem direkt Verträge andrehen wollte…
Jedenfall hatte ich dann - sichtlich enttäuscht, daß sie es bei Gravis nicht in Garantie nehmen, obwohl es mir am Telephon zugesichert wurde - die Apple Support Hotline kontaktiert. Da meinte man nur, ich solle die Rechnung einscannen und meinen Namen + Adresse zuschreiben, an sie mailen und dann das iPhone in das Paket, das am nächsten Tag schon kam, packen und mit UPS zurücksenden. Kaum war das iPhone per UPS bei Apple eingetroffen, bekam ich auch schon eine Mail, daß ein neues iPhone auf dem Weg zurück wäre - das auch schon am nächsten Tag kam.
Fazit also: Ich habe für 291€ ein nagelneues iPhone 3G 16 GB bekommen. Für 69€ bekäme ich noch den AppleCare Protection Plan, mit dem die Garantie um eine weiteres Jahr verlängert wird, was ich auch machen werde. Neu würde mich das iPhone 3G 550€ - 600€ kosten und hätte nur ein Jahr Garantie - so habe ich ein komplett neues und 1 Jahr und 3 Monate Garantie. Der Apple Support ist also echt spitze (wie immer, war schon damals bei meinen PowerBook und iBook Akkus so), während der von Gravis mal total zum Vergessen ist. Also Gravis meiden und lieber direkt zu Apple - es kostet bei Apple nicht mal Versandkosten und das mit dem Namen ändern ist auch kein Problem (das waren die beiden Gründe, warum ich es zuerst bei Gravis probiert hatte).
PS: Auch lustig ist der Hinweis in der Mail von Apple, daß ein evtl. vorhandener Jailbreak nach der Garantie weg ist, weil das Gerät getauscht wird und dann evtl. mit der eingesetzten SIM-Karte nicht mehr funktioniert. In Europa scheint die das mit dem Jailbreak also nicht sonderlich zu interessieren.
Handyhersteller und ihre Dreistigkeit
Created: 12.08.2009 23:22 UTC
Die Dreistigkeit von Handyherstellern will einfach nicht nachlassen: Das Palm Pre sendet die aktuelle GPS Position, welche Programme installiert sind, wie lange diese genutzt wurden und vieles mehr an Palm.
Und ich habe mich drüber aufgeregt, daß Apple Anwendungen vom iPhone löschen kann…
Ach ja, ich denke nicht, daß Android in Sachen Privatsphäre viel besser ist, da dort ja alles Google ist. Schade, daß OpenMoko wegen den ganzen anderen auf Linux basierenden Handy-Plattformen tot ist - denn die sind alle recht bedenklich und daher IMO nicht wirklich eine Alternative.
Wie lange es wohl dauert, bis in Symbian sowas gefunden wird, wenn es erstmal unter eine Open Source Lizens gestellt wurde? Oder dauert das so lange bis sie das tun weil sie das erst alles ausbauen müssen? Das würde erklären, warum sie planen, es Stück für Stück zu releasen - jedesmal, wenn ein Stück von der Spyware befreit wurde…
WD-Festplatten
Created: 24.07.2009 17:10 UTC
Ok, Leute, WD-Platten gehören ganz eindeutig zu den Festplatten, die man nicht kaufen möchte: Sie ist SCHON wieder abgeraucht. Grade erst die andere aus der Reperatur zurückgekommen, ist die Ersatz-Platte, die ich gekauft hatte, jetzt auch tot. Und ihr dürft 3x raten, was passiert ist: Das iPhone (ja, das iPhone!) ist von ein paar Zentimetern Höhe auf den Laptopg eknallt, als er NICHTS gelesen oder geschrieben hat. Mehr nicht! Diese Festplatten sind doch echt der letzte Schrott… NIE wieder WD! NIE!
Oh, und Backup vom Laptop hatte ich natürlich immer noch nicht, weil ich immer noch nicht genug Platz zum Backup vom Laptop machen hatte… Natürlich passiert das genau jetzt, wo ich am Wochenende vor hatte, mir eine 1 TB Platte zu kaufen, auf der ich dann alles hätte sichern können…
Manhattan Mini Cam #2
Created: 24.07.2009 15:00 UTC
Hatte ja letztens schonmal über meine Versuche berichtet, das Ding unter Linux zum Laufen zu bringen, was aber nicht ging, obwohl es PAC2007 ist. Nun, ich hatte jetzt mal Langeweile und habe das ganze unter Windows XP im VMware Player probiert (der kann USB-Geräte an das Gast-System routen): Da funktioniert das Ding noch weniger als unter Linux - der Treiber erkennt sie nichtmal und meint, er sei garnicht dafür zuständig. Und das tun alle 3 Treiber: Der auf der CD, die dabei lag, und die beiden auf der Homepage des Herstellers.
Tja, was soll man da noch sagen? Das Ding scheint wohl EPIC FAIL zu sein und nirgendwo zu funktionieren. Und damit wäre dann auch geklärt, warum es kostenlos bei einer Bestellung dabei war ;).
Ach ja, vom Hersteller, Manhattan, habe ich auf meine Anfrage, ob sie Dokumentation rausgeben können, nur eine Antwort gekriegt mit dem Link zum Windows-Treiber - nicht mit einem einzigen Wort ist man auf meine Anfrage eingegangen. Auf meine erneute Antwort, daß mir der Windows-Treiber (der ja auch nicht funktioniert), exakt garnichts bringt, habe ich nie eine Antwort bekommen. Scheint also auch wieder so ein Hersteller zu sein, der nicht will, daß man seine Produkte kauft - also tut das bitte auch alle nicht :).
Seit iPhone OS 3.0 SDK kein PPC-Support mehr
Created: 13.07.2009 13:57 UTC
Ich wollte nur mal eben drauf hinweisen, daß seit dem iPhone OS 3.0 SDK diese Anleitung nicht mehr funktioniert. Ihr könnt zwar alles nach wie vor installieren, aber dann werdet ihr feststellen, daß die Binaries keine Universal Binaries mehr sind und nur Versionen für i386 und x86_64 existieren. Wer, so wie ich, nur einen PPC Mac hat, kann jetzt also nicht mehr fürs iPhone entwickeln.
Lustiger Spam
Created: 30.05.2009 12:27 UTC
Mit dem Spam wird immer lustiger. Soeben hat mich eine Spam-Mail erreicht, die vom Server, der zum Spam-Versand benutzt wurde, mittels SpamAssassin als Spam gekennzeichnet wurde. Das ist natürlich auch ein Weg, ausgehende Mails auf Spam checken und dann trotzdem versenden, statt das Open Relay zu schließen :D.
iPhone-Entwicklung auf PowerPC und ohne Apple-Zertifikat
Created: 15.05.2009 16:29 UTC
So, ich hatte ja vor einiger Zeit schon versprochen, mal eine Anleitung zu schreiben, wie man das iPhone SDK auf einem PowerPC zum Laufen bringt mit einem gejailbreakten iPhone, ohne, daß man ein Zertifikat von Apple braucht. Da ich jetzt letztens mal das iPhone SDK neu installiert habe (ich hatte eine Mischung aus dem für iPhone OS 2.2.1 und dem für iPhone OS 3.0 drauf), habe ich das ganze mal nebenher ein wenig dokumentiert, um daraus anschließend einen Blog-Eintrag zu machen. Ich werde das ganze in 2 Teile aufteilen: Einmal den Teil, um das SDK auf einem PowerPC zum Laufen zu bringen und dann den Teil, um das ganze auf einem gejailbreakten iPhone ohne Apple-Zertifikat laufen zu lassen.
Also, zuerst zur Installation des SDK auf einem PowerPC: Zunächst installiert ihr das SDK ganz normal über die beiliegende .pkg-Datei. Während der Installation ist das iPhone SDK selber ausgegraut, aber die Installation der anderen Komponenten klappt problemlos. Um jetzt das SDK nachzuinstallieren, müssst ihr folgende Pakete aus dem entsprechenden Unterverzeichnis manuell über ein Programm wie Pacific installieren:
DeveloperDiskImage.pkg
iPhoneDocumentation.pkg
iPhoneHostSideTools.pkg
iPhoneSDK2_2.pkg
iPhoneSDKHeadersAndLibs.pkg
iPhoneSimulatorPlatform.pkg
iPhoneSystemComponents.pkg
Ich habe hier bewusst die SDKs für iPhoneOS 2.0 und iPhoneOS 2.1 weggelassen, da man sie eigentlich eh nicht braucht. Um jetzt den Simulator nutzen zu können, muß man das Xcode Spec File für den Simulator anpassen. Das findet man unter
/Developer/Platforms/iPhoneSimulator.platform/Developer/Library/Xcode/Specifications/iPhone Simulator Architectures.xcspec
Dort gibt es eine Zeile
RealArchitectures = ( i386);
die man durch
RealArchitectures = ( i386, ppc);
ersetzt. Anschließend fügt man noch folgende Zeilen nach dem Intel-Kram hinzu:
// G3
{ Type = Architecture;
Identifier = ppc;
Name = "Minimal (32-bit PowerPC only)";
Description = "32-bit PowerPC";
PerArchBuildSettingName = "PowerPC";
ByteOrder = big;
ListInEnum = NO;
SortNumber = 201;
},
// G4
{ Type = Architecture;
Identifier = ppc7400;
Name = "PowerPC G4";
Description = "32-bit PowerPC for G4 processors";
ByteOrder = big;
ListInEnum = NO;
SortNumber = 202;
},
// G5 32-bit
{ Type = Architecture;
Identifier = ppc970;
Name = "PowerPC G5 32-bit";
Description = "32-bit PowerPC for G5 processors";
ByteOrder = big;
ListInEnum = NO;
SortNumber = 203;
},
Damit aber noch nicht genug. Anschließend müßt ihr noch codesign durch einen Wrapper ersetzen. Nennt also /usr/bin/codesign in /usr/bin/codesign.orig um und packt folgendes Script nach /usr/bin/codesign (Warnung: Das Script stammt nicht von mir, sondern von hier. Aber irgendwann werde ich das auch mal selber neuschreiben, weil es eben Perl ist):
#!/usr/bin/perl
$appDir = $ARGV[$#ARGV];
@tmpAry = split(/\//,$appDir);
$baseAppName = $tmpAry[$#tmpAry];
$baseAppName =~ s/\.app$//;
$realAppName = "$appDir" . "/$baseAppName";
$sign = 0;
for($b = 0; $b < $#ARGV; $b++) {
if($ARGV[$b] eq "-s") {
$sign = 1;
}
}
$mums=`file $realAppName`;
if ($sign == 1 && $mums =~ /executable arm/) {
#print "Signing armv6..\n";
$dev = "/Developer/Platforms/iPhoneOS.platform/Developer/usr/bin/";
$tmp = "$appDir" . "/tmpbin";
`$dev/lipo -create $realAppName -output $tmp`;
`mv $tmp $realAppName`;
system("/usr/bin/codesign.orig", @ARGV);
`$dev/lipo -thin armv6 $realAppName -output $tmp`;
`mv $tmp $realAppName`;
system("rm $appDir" . "/CodeResources");
system("cp $appDir" . "/_CodeSignature/CodeResources $appDir" . "/CodeResources");
exit 0;
} else {
exec '/usr/bin/codesign.orig', @ARGV;
}
Damit sollte der PowerPC-Teil abgeschlossen sein. Nun also zum Teil, Anwendungen ohne Zertifikat von Apple auf gejailbreakten iPhones installieren zu können:
Zunächst müßt ihr ein selbst-signiertes Zertifikat anlegen. Das geht am einfachsten über die Schlüsselbundverwaltung von OS X. Als Name wählt ihr einfach „iPhone Developer“ und als Typ Code Signing. Anschließend editiert ihr die Datei
/Developer/Platforms/iPhoneOS.platform/Info.plist
und fügt dort bei den OverrideProperties folgende Zeilen hinzu:
<key>PROVISIONING_PROFILE_ALLOWED</key>
<string>NO</string>
<key>PROVISIONING_PROFILE_REQUIRED</key>
<string>NO</string>
Nun müsst ihr auf dem iPhone noch via Cydia das Paket „MobileInstallation“ installieren und in der Info.plist eures Xcode-Projekts folgendes hinzufügen:
<key>SignerIdentity</key>
<string>Apple iPhone OS Application Signing</string>
So, jetzt sollte endlich alles laufen ;). Wenn ich was vergessen habe, mailt mir!
Debian wechselt auf glibc-Fork
Created: 06.05.2009 17:00 UTC
Endlich! Ich blogge ja normalerweise keine Sachen, die schon auf irgendwelchen großen Newsportalen oder bekannten Blogs standen, aber bei sowas muß ich einfach: Debian wechselt auf eglibc. Endlich hat es eine Linux-Distribution verstanden! Ich hoffe, viele andere werden folgen…
Kaputte Software
Created: 01.05.2009 22:46 UTC
Heute mal wieder aus der Reihe „Kaputte Software“: GCC unter OS X.
Mir fällt grade garnicht ein, was ich dazu noch sagen soll. GCC gefällt der Typ von super plötzlich nicht mehr, wenn es innerhalb eines @try-Blocks ist. Laut Google hatte wohl jemand das selbe Problem in Verbindung mit @synchronize, aber eine Lösung gabs da auch nicht. Der andere Treffer ist ein japanisches Blog und außer den beiden Treffern gibt es keine bei der Suche nach der Warnung, welche wegen -Werror zu einem Fehler wird. Also mußte ein dreckiger Workaround (siehe Commit) her… *seufz*
Man findet doch echt am laufenden Band etwas, wenn man an sowas wie libobjfw arbeitet und mal hinter die Fassade der ganzen Sachen schaut. Erschreckend, wie viele Compiler- und Runtime-Bugs man dann findet. Grade mit @try gibt es da einige in GCC (siehe z.B. den Workaround für einen Bug in GCC 4.0.1, evtl. aber nur mit Apple GCC). Oder so Sachen wie der Check in configure, ob @""-Literals eine unberechtigte Warnung machen, daß _OBJC_INSTANCE_0 definiert aber nicht benutzt würde (es ist eine von GCC selber definierte, intern genutzte Variable, die natürlich sehr wohl benutzt wird, nur eben nicht in dem Source-File, sondern in dem Code, den GCC generiert).
Boxen-Umtausch bei Conrad
Created: 23.04.2009 14:11 UTC
Soeben kam meine ausgetauschte linke Box. Nachdem der Hochtöner plötzlich seltsame Geräusche von sich gegeben hatte, hatte ich bei Conrad angerufen und gefragt, wie es denn mit Gewährleistung aussehe, da ich die Boxen noch kein halbes Jahr hatte. Dadurch habe ich dann zu meiner Überraschung herrausgefunden, daß es sogar 2 Jahre Garantie auf die Boxen gibt und sie sogar das Porto für das Hinsenden und Zurücksenden übernehmen! Also am Freitag eingeschickt und heute kam sie dann schon direkt per Post wieder. Funktioniert auch bestens, sie haben also nicht einfach die selbe wieder zurückgeschickt oder sowas ;). Muß sagen, bin echt begeistert! Also wenn ihr euch neue Boxen zulegen wollt, kann ich echt nur empfehlen, mal bei Conrad zu gucken.
GNU libobjc und Apple Runtime: Beide sind kaputt
Created: 19.04.2009 17:41 UTC
Wer mal wissen möchte, wie kaputt beide Runtimes sind, dem empfehle ich, mal folgende Commit Message zu lesen. Hier auch mein Bugreport bei GCC. Sie werden es nicht vor 4.5 fixen, wenn überhaupt.
Manhattan Mini Cam
Created: 17.04.2009 21:56 UTC
Mein Vater hat mir grade so eins von diesen USB-Webcam-Dingern gegeben, eine „Manhattan Mini Cam“, wie schon im Titel steht. Die gabs wohl bei irgendeiner Bestellung gratis dazu, glaube bei Conrad wars. Google fand nicht viel dazu, wie es mit Linux-Unterstützung aussieht. Aber nach der USB-ID googlen gab dann das Ergebnis, daß der gspca_pac207 diese USB-ID unterstützt. Scheinbar benutzen auch eine Menge andere Webcams die selbe USB-ID, z.B. eine von Medion. Jedenfalls gibt sie in MPlayer nur ein komplett grünes Bild aus und das auch nur über das v4l1_compat-Layer, über v4l2 bricht MPlayer direkt ab. Cheese zeigt in den Preferences das Device „CIF Single Chip“, die Liste der Auflösungen ist aber leer. Wenn man das Device in ein File cattet kommt da auch nichts wirklich brauchbares bei raus - größtenteils schwarz und alle paar Pixel mal ein heller Punkt, wenn man das Ganze als Sequenz von RAW-Bildern interpretiert (wobei ich mir eher denke, daß die Kamera es schon komprimiert liefern wird - für unkomprimiert war das File auch viel zu klein, dann wäre höchstens 1 Frame drin gewesen). Google nach den Fehlermeldungen von MPlayer gab nur 3 Treffer, die auf Französisch, Italienisch und Polnisch waren und alle nicht sehr viel brauchbare Informationen gaben - waren alle 3 Foreneinträge ohne Lösung.
Ich tippe mal darauf, daß der Treiber sie eben doch nicht richtig unterstützt. Das Lämpchen, ob sie grade aufnimmt, scheint er zwar zu steuern, mehr aber auch nicht. Ich habe daher mal beim Hersteller nachgefragt, ob die nicht mal Dokumentation rausgeben wollen, damit man das fixen kann. Ich laß euch dann hier wissen, was daraus geworden ist. Falls noch jemand dieses Ding hat, kann er sich ja mal bei mir melden.
libobjfw: Beseitigung der Abhängigkeit von Object & iPhone-Support
Created: 10.04.2009 19:10 UTC
Ich habe in libobjfw jetzt die Abhängigkeit von Object und somit zu einem großen Teil die Abhängigkeit von der verwendeten Runtime beseitigt. Warum ich mir so einen Streß gebe? Apple hat bei ihrer ObjC2-Runtime sogut wie alles deprecated und es ist einfach ein riesen PITA, das Zeug zu benutzen. Und auf dem iPhone gibt es z.B. kein ObjC1 mehr, bei Snow Leopard wird das wohl genauso sein, zumindest in 64 bit. Wird also in Zukunft vermutlich nicht nur für das iPhone nützlich sein.
Naja, jedenfalls hatte ich mich ja letztens beschwert, daß es mir nicht Lowlevel genug wäre. Das muß ich jetzt echt zurück nehmen. Viel weiter Lowlevel geht es nicht, dann müsste ich schon gcc patchen, damit er eine komplett eigene Runtime supported ;). Ich habe jetzt alles von Object, was ich verwendet habe, neugeschrieben - einmal für die GNU Runtime und einmal für die Apple Runtime. Ich werde aber auch noch weitere Methoden von Object, die noch nicht zum Einsatz kommen, für OFObject schreiben.
Damit dürfte jetzt libobjfw das erste ObjC-Framework sein, das auf dem iPhone läuft und nicht von Apple ist! :)
Ein weiterer netter Nebeneffekt ist, daß OFConstString jetzt endlich auf OFObject basieren kann, da das jetzt einen eigenen Allokator hat, der einfach den Memory Pool und den Reference Counter vor die IVars packt. Die Variablen vor den IVars heißen bei libobjfw übrigens - sehr einfallsreich - Pre-IVars. Das ganze muß vor die IVars, weil gcc bei konstanten Strings selber die Instanz anlegt und erwartet, daß er den String und die Länge als erste IVars eintragen kann. Durch das Nutzen von Pre-IVars konnten dann auch direkt 2 Protocols entfernt werden, die man dadurch nicht mehr braucht.
So, und zum Schluß gibt es natürlich auch noch was für die Augen:
Eine kleine Ernüchterung habe ich allerdings noch: Es gibt noch 2 Kleinigkeiten, die ich fixen muß. Aber danach wird es dann einen größeren Commit geben :).
Lowlevel-Fanboy
Created: 08.04.2009 11:35 UTC
Ich bin doch einfach ein Lowlevel-Fanboy… Daran wird sich scheinbar nie was ändern. Gestern Abend saß ich ziemlich lange dran, einen Bug in 61 Zeilen ObjC-Code zu finden, die ich grade geschrieben hatte. Irgendwann hatte ich einfach keine Lust mehr und habe es auf den nächsten Tag verschoben. Heute Morgen habe ich das ganze dann einfach in C neugeschrieben, in 82 Zeilen. Und es funktionierte auf Anhieb.
Das ganze war eine Funktion für eine Klasse in libobjfw. Ergo wäre es nur angemessen gewesen, das in ObjC zu schreiben. Aber wenn ich mir so mal die ganzen anderen Implementierungen ansehe, die ich in libobjfw gemacht habe: Fast jede Klasse nutzt fast ausschließlich C. Ich habe zwar z.B. ne Klasse für Arrays, in anderen Klassen nutze ich sie aber nie und mache es doch wieder alles selbst.
So langsam glaube ich echt, daß ich irgendwann zwar libobjfw fertig haben werde, es selber aber nicht nutzen werde. Irgendwie habe ich doch immer das Bedürfnis, alles selber zu machen. Und das scheint irgendwie bei mir auch noch besser zu klappen. Und es spart meist oft unnützen Code. Wenn ichs selber mache, kann ich z.B. selber bestimmen, wann Speicher alloziert wird. Und irgendwie brauche ich das scheinbar, sonst werd ich aus meinem Denkkonzept gebracht. In OFDictionary habe ich ja z.B. OFList verwendet und da hatte ich auch mehr Probleme, das zu debuggen, als bei anderen Klassen, die eigentlich nur C verwenden innerhalb der Methoden.
Sollte ich vielleicht mit libobjfw aufhören und wieder nur C programmieren? Ich habe fast den Eindruck, das geht besser und liegt mir mehr… Andererseits finde ich ObjC schon irgendwie nett und bin damit eigentlich immer noch recht Lowlevel, so, wie ich das in libobjfw verwende… Und libobjc damit ersetzen ist ja auch geplant, das wäre dann ja sogar verdammt Lowlevel… Das Schreiben von libobjfw ist halt verdammt Lowlevel und macht mir Spaß, aber das Benutzen ist mir dann schon fast wieder nicht Lowlevel genug. Hmm… Feedback via Mail willkommen ;).
Aprilscherze
Created: 01.04.2009 12:13 UTC
Irgendwie werden die Aprilscherze von Jahr zu Jahr schlechter. Als Protest mache ich daher einfach keinen. Hatte ja für einen Moment überlegt, einen zu machen, aber nachdem alle meinen, einen machen zu müssen, egal wie schlecht er ist, habe ich mich anders entschieden.
Das Landgericht Karlsruhe und die Haftung für Links
Created: 31.03.2009 12:29 UTC
Mikael hat mal die Rechtssprechung zur Haftung für Links auf die Seite des Landgerichts Karlsruhe angewandt und dabei kam das hier raus, was er auch abgeschickt hat. Ich bin ja mal gespannt, wie die Reaktionen darauf ausfallen :). Definitiv eine interessante Aktion und ich wünsche viel Glück dabei!
Ach ja: Ich verlinke bewusst nicht auf das LG Karlsruhe, denn wenn ich das tun würde, würde ich mich ja auch strafbar machen! (Mikael hat in der PDF ja zum Glück nichts verlinkt!)
„Ohne MS Office und Windows kann man keine Informatikgrundlagen studieren!“
Created: 29.03.2009 13:18 UTC
Wer mal die lächerlichsten Grundvorraussetzungen einer Hochschule für ein Studium der Informatikgrundlagen sehen möchte, der gucke sich mal das hier an.
Ich fasse zusammen:
Fazit? Drüber lachen und boykottieren, was sonst? Wenn sie meinen, man braucht bestimmte Software, um Grundkonzepte zu verstehen, dann haben sie sie sowieso selber nicht verstanden.
Danke an cnuke für den Link!
ejabberd-Performance
Created: 25.03.2009 16:57 UTC
So, ich habe jetzt endlich die Ursache für die Performance-Probleme mit ejabberd gefunden: Mnesia. Ja, nicht das Aufbauen von s2s-Verbindungen ist das Problem, nein, Mnesia! Ok, gut, das kann jetzt natürlich sein, daß es eine Kombination aus beidem ist und das Aufbauen der s2s-Verbindungen Mnesia blockt, aber sowas sollte bei Erlang ja eigentlich nicht passieren. Jedenfalls nutze ich jetzt einfach eine externe DB statt Mnesia und es ist um Größenordnungen schneller :). Das ist ja das schöne, ejabberd lässt ja so gut wie jede externe Datenbank zu.
Also: Wenn ihr Performance-Probleme mit ejabberd habt, dann solltet ihr das evtl. auch mal probieren.
ejabberd & PEP
Created: 10.03.2009 16:43 UTC
Also nachdem mir ejabberd in letzter Zeit immer weniger gefiel aufgrund der Häufung von Bugs und der immer schlechter werdenden Performance, muß ich jetzt doch mal was positives über ejabberd sagen: Und zwar hat Christophe Romain gestern endlich alle PEP-Bugs, die ich gemeldet hatte, auf einmal gefixt. Zumindest scheint es so, ich habe auf Anhieb keinen der Bugs mehr reproduzieren können. Wenn sie jetzt noch die Performance und ein paar andere kleine Bugs wieder in den Griff kriegen und man demnächst nicht mehr ein halbes Jahr warten muß, bis sich eines nervigen Bugs angenommen wird, bin ich echt wieder rundum glücklich mit ejabberd :). (Jaja, selber fixen, ich weiß. Habe ich ja mit einigen auch schon gemacht ;). Habe mittlerweile auch schon das halbe Team von ProcessOne in meinem Roster wegen all der Bugs *g*.)
Direkt auf dem iPhone compilieren
Created: 05.03.2009 20:55 UTC
Wer Programme direkt auf dem iPhone compilieren möchte, der sollte sich vielleicht mal das hier ansehen. Damit ist es möglich, Anwendungen in einem Rutsch zu compilieren und zu signieren, sodaß man nicht mit den sysctls rumspielen muß (was ein paar Side-Effects hat). Sehr praktisch, wenn man direkt auf dem iPhone compilieren möchte, denn so klappen auch configure-Scripts und andere Sachen, die etwas compilieren und direkt ausführen möchten.
So sieht das ganze auf dem iPhone dann übrigens aus:
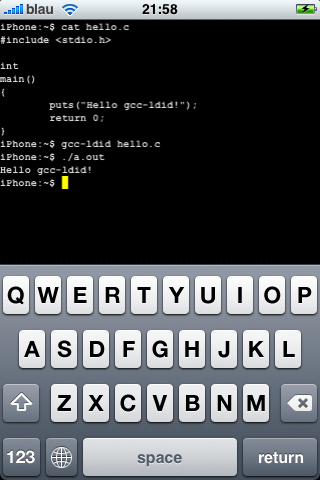
iPhone Development
Created: 26.02.2009 15:53 UTC
So, endlich habe ich es geschafft, auf meinem iPhone eine selbstgeschriebene Anwendung zum Laufen zu bringen. Das war garnicht so einfach, weil ich nur einen PowerPC Mac habe, ein PowerBook, und PowerPC vom iPhone SDK offiziell nicht unterstützt wird. Aber alle Binaries des SDK sind Universal Binaries. Daher ist es möglich, die einzelnen .pkg Dateien, die der Installer auslässt (er installiert auf PPC nur XCode) manuell via Pacific oder einem ähnlichen Tool zu installieren. Dann läuft zwar der Simulator und alles (aber auch nur, nachdem man ein paar Files editiert hat, die XCode sagen, daß PPC auch eine supportete Architektur ist), aber es auf dem iPhone laufen zu lassen ist nochmal was anderes. Da ich nicht im Apple Developer Program bin und ich eh erstmal nur was rumspielen will, habe ich dementsprechend kein Zertifikat. Das ist erstmal das erste, worüber er meckert. Da kann man aber einfach ein self-signed Zertifikat für Code-Signing im Zertifikatsassistenten von OS X anlegen und XCode gibt Ruhe. Dann kommt aber wieder ein Problem, da ich einen PPC habe: codesign klappt hier nicht - er mag das, was er signen soll, nicht erkennen. Ich habe aber ein kleines Wrapper-Script für codesign gefunden, das erst via lipo eine Universal Binary draus macht, es signiert und dann wieder eine kleine Binary für das iPhone draus macht - dann gehts und er erkennts. Wenn man so weit ist, nimmt das iPhone aber immer noch nicht die Anwendung - ist ja klar, ist ja nur ein self-signed Zertifikat. Was macht man da? Auf einem original iPhone hat man da Pech. Auf einem gejailbreakten hingegen kann man das Programm „MobileInstallation“ via Cydia installieren und einen Eintrag in der Info.plist des Programms, das man auf das iPhone laden will, hinzufügen und es geht.
Btw: Ohne Jailbreak ist ein iPhone meiner Meinung nach eh komplett nutzlos. Ohne kam ich nichtmal in mein WLAN, weil man unmöglich 63 Byte tippen kann, ohne einen Tippfehler zu haben (siehe meinen Eintrag davor). Aber mit Jailbreak gibt es dann eine Zwischenablage (einfach in Cydia Clippy installieren) und dann kann man folgendes machen: Auf dem Mac im Adressbuch einen Eintrag WLAN machen und dem als Straße den WLAN-Key geben. Dann synct man das iPhone via iTunes und geht auf dem iPhone in den Kontakt, packt den Key in die Zwischenablage und fügt ihn einfach ein, wenn man ins WLAN will. Ein Jailbreak hat auch sonst nur Vorteile: Dann kann man z.B. auch Videos aufnehmen, MMS senden und empfangen, Bluetooth ist auch in Arbeit, hat ein Terminal auf dem iPhone (sogar root!), kann einen OpenSSHD laufen lassen, kann Emulatoren für SNES, NES, GB und PSX laufen lassen, kann Doom und Quake laufen lassen und vieles, vieles mehr! Also der Jailbreak macht das iPhone meiner Meinung nach erst nutzbar ;).
Input über glibc-Rant
Created: 26.02.2009 12:36 UTC
Grade eben erreicht mich eine e-mail mit der Anmerkung, mein glibc-Rant sei doch vollkommen unbegründet und die Manpage würde doch ganz klar sagen, wie man sie zu verwenden hätte.
Nun, bevor auch andere den Rant von damals falsch verstehen: Es geht hier nicht um C, es geht hier um Objective-C. Da hat #import durchaus seinen Grund. Und es hat Vorteile. Und daher ist das Argument, daß #import unportabel wäre, weil der MSVC++ es nicht könne, ziemlicher Blödsinn: MSVC++ kann Objective-C nämlich überhaupt nicht.
Da in dem Input über meinen glibc-Rant auch stand, daß #import doch nur Nachteile hätte und die Manpage ja auch #include nennen würde, scheint es hier wohl einige Unklarheiten zu geben, denn eigentlich hat es nur Vorteile. Ich will das mal hier erklären:
Jeder von euch kennt bestimmt das Problem, wenn man einen Header mehrfach includet. Nehmen wir einfach mal folgendes Beispiel:
foo.h:
extern int foo;
Wenn man das jetzt 2 mal includet (was häufig implizit vorkommt, weil sich Header gegenseitig auch includen), hat man zumindest eine Warnung, wenn nicht - je nach Compiler - sogar einen Fehler. Daher hat es sich eingebürgert, daß man folgendes schreibt:
foo.h:
#ifndef __FOO_H__
#define __FOO_H__
extern int foo;
#endif
Das muß man dann in jedem Header machen, was auch mitunter eine der meist kritisierten Sachen an C ist. Zumal es hier schon Probleme gibt, wenn 2 Header in verschiedenen Verzeichnissen den selben Namen haben. Dann muß man noch was anderes in den Define zur Identifikation packen, z.B. den Pfad oder den Namen der Library von der der Header ein Teil ist. Scheinbar waren auch die Leute von NeXT damals relativ genervt davon, weshalb sie eine neue Präprozessoranweisung einführten: #import.
Nun, wie aber unterscheidet sich #import von #include? Es ist eigentlich ganz einfach: Es macht das Konstrukt mit #ifdef und #define überflüssig, indem der Präprozessor sich merkt, ob das File bereits includet wurde. Ist das der Fall, macht #import einfach garnichts. Somit spart man sich die Konstruktion mit dem #ifdef und #define. Und ob ein anderer Header auch so heißt, darum muß man sich nicht kümmern, denn der Präprozessor weiß, um welchen Header es sich handelt.
So, was hat das aber mit dem glibc-Rant zu tun? Daß die glibc ziemlich kaputt ist, wenn man #import verwendet. Und zwar scheinen die Header gegenseitige Abhängigkeiten der Defines zu haben, sodaß einige Defines der glibc nicht passen und die glibc dann einige essentielle Sachen einfach nicht definiert. Die glibc kommt einfach mit ihren eigenen Defines durcheinander. Daher muß man dann für die glibc-Header immer #include nehmen statt #import. Was daran so schlimm ist? Man nutzt in Objective-C generell immer #import. Und es läuft auch problemlos auf allen Plattformen damit. Nur sowie es dann daran geht, daß man das ganze mit der glibc kompilieren möchte, hagelt es plötzlich Fehler. Fehler, die man sich auf Anhieb nicht erklären kann. Bis man irgendwann merkt, daß das Ändern der Reihenfolge, in der man importiert, das Problem behebt. Scheinbar. Bis es unter irgendwelchen ganz obskuren Umständen wieder bricht. Und dann sucht man wieder ewig. Also kann man nur #include nehmen, was dann doch sehr unschön ist, wenn man beides in einem File hat. Und wirklich jede andere libc kriegt das problemlos hin :). glibc hingegen versagt schon, wenn man nur wchar.h und string.h importiert im selben File.
So, ich hoffe, das sorgt jetzt für ein bisschen Aufklärung, was das Problem eigentlich wirklich ist. Und wie gesagt, es ist nur eines von Milliarden Problemen der glibc - eines der größten ist IMO das #define _GNU_SOURCE und das Fehlen von strl*, weil Drepper zu blöd für Strings ist.
iPhone + WLAN = *megakotz*
Created: 23.02.2009 18:16 UTC
Also ich kann grade echt einfach nur noch kotzen. Erst gibt man zwanzigtausend mal den Hash ein, was das iPhone nicht macht. Toll, Plaintext ging bei dem WLAN-Passwort nicht. Also auf ein anderes gestellt, das man dann auch in Plaintext darstellen kann. An dieser Stelle: Danke, Apple, ihr macht grade mein WLAN unsicherer. Aber als ob das noch nicht reicht, nein, so einen sch*** 63 Byte String auf dem iPhone einzugeben ist die Hölle! Es ist absolut nicht möglich, das mal ohne einen Vertipper einzugeben. Geht einfach nicht. Dafür ist der Touch-Sensor viel zu ungenau. Und als ob das nicht reicht muß Apple jedes verf***te Zeichen bei der Eingabe durch ein • ersetzen. WAS SOLL DAS? So kann ich nicht korrigieren und nix‼ Ich frage mich echt, was der Sch*** soll. Was bitte ist so schwer daran, Apple, daß man WLANs einfach über iTunes oder sonstewas synchronisieren kann? Für mich ist das einfach nur absolutes Versagen, was Apple da in Sachen iPhone + WLAN geschafft hat. Vollkommen unbrauchbar.
iPhone & Nokia E61i
Created: 23.02.2009 14:16 UTC
So, heute sind das iPhone und das Nokia E61i gekommen. Beschäftige mich jetz im Moment erstmal mit dem iPhone. Mit dem WLAN einrichten ist schonmal richtig PITA. Ich habe ein WPA2-PSK geschütztes WLAN mit einem Random-PW in Hex. D.h. ich darf 64 Zeichen eintippen. Beim 1. mal war wohl ein Typo drin, beim 2. mal war der Button „Join“ nach Eingabe des gesamten PWs dann ausgegraut - verdammt!
Der Plan ist jedenfalls, einen Buddycloud-Client für das iPhone zu schreiben. Dafür habe ich es auch gekriegt ;). Und das Nokia dazu, um die Original-Anwendung auch benutzen zu können. Aber das wird in naher Zeit eher weniger was werden, Karnevals-Nachwirkungen und dann die Vorabiklausuren und das Abi. Aber immerhin habe ich das iPhone SDK schon auf meinem PowerBook ans laufen gekriegt - ja, das geht auch auf PPC mit etwas tricksen! ;)
glibc-Rant & libobjfw
Created: 14.02.2009 18:19 UTC
So, ich muß mich jetzt einfach nochmal über glibc auslassen. Dieses Ding ist echt sowas von abnormal kaputt! Nachdem ich jetzt so lange dransaß, daß libobjfw auch mit glibc rennt, indem ich alle möglichen Reihenfolgen der #imports durchprobiert hatte, darf ich jetzt feststellen, daß das unter gewissen Umständen immer noch failed. Ergo habe ich jetzt alle Header der libc über #include statt über #import drin.
Klar, es läuft jetzt. Aber trotzdem: Was soll der Sch***? Warum darf ich stdarg.h nicht als 2. importen, sondern muß es zwangsweise immer als erstes, aber wenn ich stattdessen #include nehme gehts? Warum darf ich nicht in einem File wchar.h und string.h importen, sondern immer nur eins von beidem pro File? Wie kann man bitte so kaputte Header schreiben? Warum bitte schreiben die Header, die unter so vielen Umständen einfach nur die Hälfte definieren oder sogar Syntax-Error erzeugen? Und das ist ja nun wirklich nicht das einzige in glibc, das einfach nur extremst kaputt ist. Warum bitte ist das auch heute noch die Standard-libc unter Linux? Es gibt so viele bessere libcs (eigentlich so gut wie jede), aber dieser Crap muß der Standard unter Linux sein? Da bekommt nan echt Lust, den glibc-Support in all seinen Projekten einfach zu droppen - es gibt ja massig brauchbare Alternativen und wenn das genug tun, ändert sich vielleicht auch mal was dran, daß glibc unter Linux der Standard ist. Das wäre eine Win-Win-Situation für alle, wenn glibc nicht mehr der Standard wäre und immer mehr Projekte den Support dafür droppen. Dann braucht man auch keine eigene Implementation von strl* mehr mitbringen, nur, weil Drepper zu blöd für Strings ist. Denn selbst der Linux-Kernel hat strl* drin.
In libobjfw habe ich jetzt übrigens mal das OFComparable-Protokoll eingeführt. Damit kann man Objekte mittels isEqual: und compare: vergleichen - das braucht man z.B. zum Sortieren oder wenn man die Objekte in eine Hashtable packen möchte. Im Moment gibt es zwar noch keine Hashtables, aber die kommen bald ;). Eine gute Hash-Funktion habe ich auch schon. OFNumbers braucht auch noch ein isEqual: und compare:, allerdings ist das dort aufgrund der vielen Integer-Typen richtig Arbeit. Muß ich mich daher noch zu überwinden, das mal in Angriff zu nehmen ;).
Neue PowerBook-Tastatur
Created: 10.02.2009 20:27 UTC
So, nachdem erst die „6“-Taste kaputt war und dann, nachdem ich sie ersetzt hatte, beim Wechseln der Festplatte leider die F2-Taste kaputt gegangen ist, habe ich jetzt beschlossen, gleich eine neue PowerBook-Tastatur zu kaufen. Nun, die kam heute an und ist jetzt drin - ihr braucht mich also jetzt nicht mehr auf Events drauf ansprechen, daß mir ne Taste fehlt :þ. Der Anschlag ist zwar ein bisschen anders als bei der davor (die davor war vermutlich einfach schon zu viel getippt), ist aber recht angenehm. Ist allerdings auch ein anderer Tastatur-Typ (gab 2 verschiedene Typen in den 12" PowerBooks).
FOSDEM zuende, XMPP-Summit
Created: 09.02.2009 17:22 UTC
So, jetzt sitze ich grade im Thalys nach Hause. Das WLAN ist zwar sehr instabil (aber hey, ich war auf der FOSDEM, ich bin jetzt sau schlechtes WLAN gewohnt!) und in der 1. Klasse gibts dann auch Stromanschluß. Das ist schonmal gut, da ich auf dem Summit dann doch einiges an Akku verbraucht habe. Mal gucken, wie das Essen wird ;).
Der zweite FOSDEM-Tag war ziemlich interessant und ich habe einige interessante Unterhaltungen über XMPP und auch Objective-C führen können. Unter anderem habe ich jetzt evtl. endlich eine Lösung für das Problem, daß die Runtime streikt, wenn ich libobjfw als DLL baue. Auch habe ich jetzt vermutlich was, um auch -upper und -lower bei UTF-8-Strings machen zu können.
Beim XMPP-Summit hingegen habe ich ehrlich gesagt den Eindruck, daß man nicht so viel geschafft hat. Man hat sich zwar immer schön in kleinen Grüppchen getroffen und in jeder ein anderes Thema diskutiert, nur leider wurden die, die mich interessieren, schon am Freitag diskutiert. Und es blieb natürlich nicht aus, daß ich mich mit Dave Cridland direkt mal wieder über End-to-End-Encryption gestritten habe. Ich denke, ich werde hier seine Ansicht, daß es eigentlich genügen würde, wenn jeder Client so viele CAs wie möglich hätte und dann der Initial Trust (also daß man einfach davon ausgeht, daß die Key-ID beim ersten mal wohl stimmt) genügen würde, nicht weiter kommentieren - ich denke, jeder, der mal wirklich drüber nachdenkt, wie „toll“ das funktioniert, wird zu dem selben Schluß kommen wie ich. Peter meint zwar, Dave hätte das bestimmt nicht so gemeint, aber „If you're not going to include as many CAs as possible in Gajim, nobody will use it“ ist ziemlich eindeutig für mich. Da es zwecklos war, das weiter zu diskutieren, haben wir das dann einfach aufgegeben.
Auf der anderen Seite habe ich nach dem Dinner auf dem Weg in eine Bar eine interessante Diskussion über End-to-End-Encryption mit Dirk Meyer geführt. Auf der Mailingliste hatten wir doch des öfteren andere Ansichten, wie sich jetzt aber rausstellte, haben wir eigentlich beide das ziemlich gleiche Ziel, nur eben verschiedene Use Cases und waren uns eigentlich in Sachen End-to-End-Encryption ziemlich einig.
So, jetzt kam grade meine Essen. Und Kaffee gab es auch :). Nicht schlecht. Also Thalys 1. Klasse kann man echt gut fahren.
So, also zurück zur FOSDEM. Also insgesamt habe ich zwar nicht viele Talks gesehen, dafür aber um so mehr und um so interessante Unterhaltungen geführt. Brüssel ist zwar nicht so toll, aber für die FOSDEM kann man da dann doch mal hinkommen ;). Es ist schon lustig, wie schwer es ist, Samstags Abends in Brüssel noch was Eßbares aufzutreiben.
Das XMPP-Dinner war auch ziemlich nett. Interessante Unterhaltungen bei gutem Essen und das auch noch gesponsort - was will man denn bitte mehr? Kein Wunder also, daß das Dinner ziemlich produktiv war. Nachdem man erstmal erstaunt war, daß ich so „jung“ bin (so jung ist 19 doch jetzt nun auch wieder nicht oO), kamen dann schnell ziemlich interessante Unterhaltungen (gut, das mit dem so jung kam nachher nochmal, als ein paar auf meinen Objective-C Code geguckt hatten, da sie scheinbar nicht mit gerechnet hatten, daß jemand „so junges“ das so weit optimiert und so weit in den internen Kram geht). Ziemlich viele Leute haben doch sehr interessante XMPP-Projekte und ich bin doch von einigen gefragt worden, ob ich nicht Lust hätte, an ihren (teils kommerziellen) Projekten mitzuwirken. Mal schaun :). Ich habe jedenfalls definitiv jetzt noch mehr neue Jabber-IDs dazubekommen als auf dem Congress. Und definitiv verdammt viele interessante Leute kennen gelernt.
So, ich denke, ich habe jetzt vermutlich vieles vergessen. Vielleicht trage ich das nach. Aber im Moment fällt es mir einfach verdammt schwer, Deutsch zu schreiben. Man fängt irgendwann an auf Englisch zu denken und sogar zu träumen oO. Man fängt an, mit Leuten, die Deutsch können, nur noch Englisch zu sprechen. Das ist echt schlimm. Mehr kann ich jetzt wirklich nicht mehr auf Deutsch schreiben. If I'd continue writing here, I'd propably continue in English without even noticing it ;). (Note to self: Maybe an English blog might be a solution to at least that problem? :þ)
FOSDEM
Created: 07.02.2009 19:31 UTC
So, endlich komm ich zum Bloggen. Also ich muß schon sagen, mit dem Thalys kommt man echt gut nach Brüssel. Für 15€ hingekommen, dagegen kann man echt nix sagen. Auf der Rückfahrt sinds dann 9€ mehr, dafür dann aber 1. Klasse (2. Klasse war schon ausgebucht) - hat aber dann so nette Nebeneffekte wie gratis Essen, gratis Trinken und WLAN.
Der Bahnhof Brussels Midi hingegen ist eine Katastrophe. Man wird von einem zum anderen Schalter geschickt, wenn man fragen möchte, wie man wo hinkommt. Am Ende heißt es dann, man soll zum Schalter gegenüber gehen, der mache in 15 Minuten auf. Ne halbe Stunde später stand da aber immer noch „fermé“ (geschlossen), sodaß ich ein Problem hatte. WLAN gab es nur gegen Bezahlung, war also auch nicht so sinnvoll. Jedoch konnte man dort zumindest kostenlos Routen planen - was aber ein wenig komisch war, da ich laut der Route mehr Fußweg hatte, als ich mit dem Zug / Bus gefahren wäre. Schließlich mußte ich dann benz anrufen und ihn fragen, dessen Weg dann auch ziemlich problemlos ging und quasi garkeinen Fußweg hatte ;).
Angekommen war ich erstmal enttäuscht, daß alles so auseinander gezogen war. Alles in mehrere Gebäude verteilt, die alle über den Campus verstreut waren. Drinnen war es recht eng, obwohl es nicht viele Stände gab. Auf der Suche nach dem Hacker Room ist mir dann romeda über den Weg gelaufen und wir haben, nach ein paar mal im falschen Gebäude sein, dann endlich den Raum gefunden, wo die XMPP-Talks sind. Nach 2 Talks hat mich der Hunger dann aber doch schon zur Essenssuche getrieben, weil ich den ganzen Tag noch nichts gegessen hatte ;). Als ich dann wieder dort war, habe ich dann auch endlich mal den Hacker Room gefunden. Und ratet mal, wen man dort direkt trifft? hacky. Die trifft man echt auf jedem Event :D. Auch wenn sie vorher sagt, sie kommt nicht :þ.
Im Hacker Room habe ich dann mal versucht, meine e-mails zu lesen. Versucht, weil die Verbindung ständig abriß. So lange, daß er mal alle Mails ziehen konnte, hat die Verbindung nie gehalten. Allerdings für eine wichtige Mail hat es gereicht. metajack hatte mir geschrieben, daß er schonmal zum Hotel ist und mir eine Wegbeschreibung hinterlassen, weil er mich nicht mehr finden konnte. Er lässt mich freundlicherweise im Hotel wohnen und teilt ein Doppelzimmer mit mir - nochmal vielen Dank an dieser Stelle! Nachdem ich dann benz gefragt habe (er hat von denen, die ich kenne, die besten Französisch-Kentnisse und kennt sich am besten in Brüssel aus), wo denn die Tram fährt, habe ich mich auf den Weg gemacht und durfte bis zur letzten Station fahren ;). Aber es hat sich gelohnt. Das Hotel ist echt nett, 4 Sterne.
So, ich bin jetzt im Zimmer, hier ist wenigstens WLAN. Jetzt kann ich meine e-mails lesen etc. ;) Ich werd jetzt erstmal warten, bis metajack kommt, ich bin hier nämlich jetzt erstmal alleine auf dem Zimmer (er hatte mir den Schlüssel an der Rezeption hinterlassen). Weitere Berichte von der FOSDEM gibt es später ;).
Build-System
Created: 30.01.2009 16:14 UTC
Nanu, was ist denn jetzt los? Ich krieg in letzter Zeit verhäuft Mails bezüglich meines Build-Systems. Früher Jahre lang nichts und jetzt melden sich plötzlich mehrere auf einmal mit Patches? Habe ich was verpaßt und irgendein größeres Projekt nutzt jetzt mein Build-System? Wenn ja, schreibt mir doch mal bitte ne Mail, welches das ist ;).
libobjfw: API-Änderung
Created: 24.01.2009 15:35 UTC
So, ich hab jetzt mal die API von libobjfw daran angepaßt, daß es jetzt OFAutoreleasePools gibt. Das wird einige Cocoa-gewöhnten Entwickler sicherlich erfreuen, da sie sich jetzt wie zu Hause vorkommen sollten ;).
Lebenszeichen
Created: 18.01.2009 22:04 UTC
Nein, das Blog ist nicht tot ;). Es gibt lediglich zur Zeit nicht wirklich was, was es wert wäre, daß ich darüber schreibe, daher lasse ich das lieber, bevor ich euch mit überflüssigem Kram langweile. Wenn, dann will ich ja auch was halbwegs interessantes schreiben.
Only in the USA (Oakland)
Created: 09.01.2009 21:36 UTC
Polizei erschießt gefesselten, auf dem Boden liegenden Mann. Vor einer ganzen U-Bahn voll Zeugen! oO
Rettung der Daten & Einrichten des neuen Systems
Created: 09.01.2009 15:39 UTC
So, die Rettung der Daten ist abgeschlossen. „/“ hatte nen ziemlichen Schaden, fast alles in „/Applications“ war kaputt, genauso das meiste von „/System“ und „/Library“ - kurzum, das System war total fritte. Aber damit hatte ich eh schon gerechnet und auf der neuen Platte ein neues aufgesetzt - nachdem ich gestern erst die Leopard-DVD nicht wiederfinden konnte. Zum Glück war „/Users/.js/js.sparsebundle“ zumindest soweit lesbar, daß es mit „sudo hdiutil attach /Users/.js/js.sparsebundle -mount require“ mountbar war (merkt euch den Command, falls ihr mal ein FileVault retten müsst - einen Umstieg auf encfs hab ich ja schon länger vor, das hat mich jetzt nochmal drin bestärkt… Wo bleibt eigentlich Full Disk Crypto für OS X?). Jedoch war nach dem Mounten auch viel kaputt, fast alle Dateien, die etwas größer waren. Aber zum Glück waren die meisten der Sachen, die ich nicht auf dem Desktop hatte und auch nicht von wo anders wiederzubekommen sind (einige Schulsachen, einige Photos, etc.), bis auf 4 Files lesbar. Die ganzen Downloads waren kaputt, genauso fast alle Musik, die ich im Home hatte - aber das sind ja Gott sei Dank alles Sachen, die wiederherstellbar sind :). Die andere Partition war interessanterweise vollständig in Ordnung. Vermutlich ist also nur ein Teil der Platte kaputt.
Alles in allem, ich hab wieder ein OS X auf meinem PowerBook auf einer neuen 250 GB Platte und auch schon alles eingerichtet und alles läuft sauber :). Aber man sollte echt nicht unterschätzen, wie viel 250 GB sind, das war richtig Arbeit, das alles manuell durchzugehen! Kostenpunkt: 73€, eine Menge Arbeit und 4 nicht wiederherstellbare Dateien, die ich auch von nirgendwo anders wiederkriegen kann, sowie tausende von anderen kaputten Dateien, die aber entweder unwichtig oder von wo anders wiederbeschaffbar sind. Und das alles wegen einmal vom Mini-Tisch fallen, nichtmal nen halber Meter… Wozu hat Apple noch gleich die Beschleunigungssensoren eingebaut?
Naja, die Tage werde ich dann mal die Sektoren der Platte, die noch intakt sind, wipen und die HD einschicken. Schließlich hatte sie schon vor dem Sturz eine Macke und hat ab und zu komisches periodisches Klicken von sich gegeben. Ich wußte also, daß sie eh bald den Geist aufgibt und hatte auch ein Backup geplant, bin nur nie dazu gekommen. Ich wollte die eh schon länger mal einsenden, aber dann ist die halt immer so lange weg… Aber da ich ja jetzt ne neue habe, stört mich das ja nicht, wenn die alte dann eingesendet ist ;). Die ist ja jetzt eh ganz kaputt. Gut, kann sein, daß sie sagen, das sei ein Sturzschaden und daher nix machen, aber vielleicht hab ich ja Glück, weil sie schon vor dem Sturz ne Macke weghatte :).
Fazit: Ich sollte nicht nur von den HDs im Desktop ein vollständiges Backup haben, sondern auch vom Laptop…
(Es gehen immer die Platten kaputt, von denen man kein Backup hat. Macht man regelmäßig Backups von einer Platte, geht sie jedoch nie kaputt ;))
Performance von Objective-C
Created: 07.01.2009 21:01 UTC
Eben hat mir gernot folgenden Link zukommen lassen. Ziemlich interessant, wie sich via IMP gecachte Methodenaufrufe zu C++ virtual Method Calls schlagen. Gut, das ganze ist jetzt mit der Apple Runtime, aber ich denke nicht, daß das bei der libobjc von GNU so viel anders aussieht. Bei den normalen Objective-C Message Sends dürfte da ein Unterschied sein (und ich denke, auch der ist nicht allzu groß), aber bei den IMP-cached wohl kaum. Da hat man ja direkt die Adresse vom Code und springt quasi nur noch dahin. Und wirklich merken tut man die Method Calls ja eh nur in Schleifen - und in denen kann man fast immer auf die IMP-cached Message Sends ausweichen, von daher :).
USB-Polizeilicht? WTF!
Created: 07.01.2009 15:10 UTC
Immer wenn man denkt, es kann keine sinnloseren USB-Spielzeuge mehr geben, dann kommt doch noch einer daher und hat sowas. Diesmal Conrad: Eine USB-Polizeileuchte, die man gratis bei einer Bestellung dazu bekommt. Nun, jetzt habe ich so ein Ding hier. Aber so langsam glaube ich, ganz so sinnlos ist das Ding doch nicht. Das Ding kann zwar nicht über Software an- oder ausgeschaltet werden, aber ich ich sollte über Software den Saft an einem USB-Port an- oder abschalten können, wenn ich mich nicht irre. Und somit hat man dann ein paar lustige Möglichkeiten, wie z.B. Polizeileuchte bei neuer Nachricht in Jabber, wenn das Compilieren fertig ist oder wenn es wichtige Security-Updates gibt :).
OFAutoreleasePool
Created: 06.01.2009 22:40 UTC
So, objfw hat jetzt Autorelease-Pools. Das Konzept werden sicherlich einige von euch von Cocoa her kennen. Naja, jedenfalls ist das ganze viel mehr tricky gewesen, als ich dachte - u.a. weil das ganze ja pro Thread ist und weil OFArray ein void* nimmt und ich ihm ein OFObject* gegeben habe und daher der Compiler mich auch nicht gewarnt hat, daß ich da Mist mache und ein OFObject** brauche. So hat mich ein fehlendes „&“ doch einige Zeit gekostet. Zumal die Fehler interessant sind, wenn man die ersten 4 Byte (ich entwickel auf einem 32 bit System) eines Objekts in ein Array kopiert und nachher einen Pointer auf diese 4 Bytes rausholt und in ein OFObject* castet. Die Klasse des Objekts kann natürlich danach noch nach wie vor richtig bestimmt werden, weil die ja am Anfang der struct eins Objective-C Objekts ist, nur sind alle Daten des Objekts natürlich Müll. Hat mich einige Zeit gekostet, bis ich draufkam, daß da einmal Pointer nehmen und einmal dereferenzieren zu wenig war, zumal „Hm, komisch, das Objekt ist doch vom richtigen Typ. Aber alle Daten sind Müll?“. Der Compiler hat wie gesagt nix gesagt (ist ja auch richtig so, war ja ein void*) und es schien ja, als ob man das richtige Objekt bekommen hat, wenn man ein [obj name] gesendet hat, von daher geht man nicht davon aus, daß man garnicht das Objekt hat, das man denkt zu haben. Ansonsten ist die Sache eigentlich doch ziemlich trivial. Es sind nur immer diese kleinen, unscheinbaren Fehler, die einen ewig aufhalten.
Anyway, für den OFAutoreleasePool-Test ist mir dann nachher noch was ziemlich cooles eingefallen, um da ein wenig Debug-Output zu bekommen. Man will ja schließlich sehen, ob richtig retained und released wurde. Jedenfalls: Wer mal sehen möchte, warum Objective-C einfach nur cool ist, der gucke sich das hier an ;).
„2.5" P-ATA Platten? Ham wir nicht!“
Created: 06.01.2009 17:41 UTC
Tja, ich hatte ja gestern angekündigt, mir heute ne neue Platte zu holen für das PowerBook. Naja, es stellte sich raus, daß das garnicht so einfach ist. Alle Läden, bei denen ich gefragt hab, haben keine. Die Aussagen gingen von „2.5" P-ATA Platten haben wir schon lange nicht mehr“ über „Wir haben gestern die letzte verkauft“ und „Vor 5 Minuten haben wir die letzte verkauft“ (verdammt!) bis hin zu „Wir können bis morgen 16 Uhr eine besorgen“. Na wenigstens etwas. Ein einziger Laden, der sie zumindest besorgen kann! Aber ich frage mich: Was ist los? Warum kauft keiner mehr 2.5" P-ATA Platten? Die sind in so vielen Laptops oder Rechnern, wo einfach kein Platz für 3.5" ist (EFIKA z.B.), warum kauft die keiner mehr? Sind alle mit den kleinen Festplatten, die von Haus aus drin waren, zufrieden oder was? Ich verstehs einfach nicht…
Platte kaputt? Egal!
Created: 05.01.2009 22:22 UTC
Auch wenn die Platte im Notebook kaputt ist, auf dem ich kurz vorher noch an libobjfw gearbeitet hatte, hält mich das nicht davon auf, das, was ich gecodet hatte, eben nochmal schnell neu zu machen. Ich hoffe, daß mir dabei keine Fehler unterlaufen sind - die Tests laufen jedoch fehlerfrei durch ;). Jedenfalls lasse ich mich diesmal durch einen Plattencrash nicht von einem Projekt abhalten :þ. Bei libxmppc hatte ich ja grade einen riesen Patch fertig, als mir mein Dateisystem verreckt ist, bevor ich ihn committen konnte, weshalb das Projekt dann so ziemlich gestorben ist. Aber von libobjfw hält man mich nicht so einfach ab :þ.
Festplatten…
Created: 05.01.2009 21:02 UTC
Im Moment rauchen aber auch wirklich alle Festplatten bei mir ab. Erst die 80 GB 2.5" im EFIKA, jetzt die 250 GB 2.5" im PowerBook. Toll. Habe jetzt keine einzige funktionierende 2.5" Platte mehr. Und beide in einer Woche verreckt.
Morgen werd ich mir erstmal ne neue 250er kaufen und die einbauen. Über USB konnte ich noch ein paar Daten von der Platte lesen, die werd ich dann morgen auf die neue 250er ziehen. Und dann werden erstmal die Restdaten von der kaputten entfernt (man weiß ja nie, trotz Crypto - und einige Blöcke tun es ja noch ohne Probleme, können also auch 7x mit Pattern überschrieben werden, schaden kanns nicht) und sie dann eingesendet. Dann hat man wenigstens wieder eine auf Reserve, wenn sie aus der „Reparatur“ (sprich: Der Hersteller wirft sie weg und schickt ne neue Platte) zurückkommt.
Ich könnte sowas von kotzen, echt…
MorphOS, EFIKA & Portierungen von libobjfw
Created: 03.01.2009 00:59 UTC
So, es ist mal Zeit für einen Rant. Ich versuche grade, zum 2. mal, MorphOS auf dem EFIKA zum Laufen zu bringen. Die Installation ging ja auch - sofern man davon absieht, daß es während der Installation in den Demo-Mode ging, in dem alles unnutzbar langsam ist - recht problemlos, aber danach? Alle paar Minuten tuts die Maus oder Tastatur nicht mehr und wenn man die Tastatur replugt, crasht es. Heute hab ichs dann nochmal mit ner anderen Tastatur und ner anderen Maus probiert, da das ja angeblich USB-Probleme des EFIKAs mit gewissen USB-Geräten sein sollen (die aber komischerweise in der OpenFirmware und in Linux ohne Probleme gehen…). Ja, ich habe tatsächlich meine andere USB-Maus wiedergefunden! Die Maus-Situation war hier ja schon so schlimm, daß ich die alten seriellen Mäuse wieder auspacken mußte :)
Jedenfalls ist es auch mit einer anderen Tastatur und Maus kein bisschen anders und die 3D Layer sind auch schon aus. Linux hingegen läuft auf dem EFIKA ohne Probleme. Und da es scheinbar jetzt im Mainline-Kernel EFIKA-Support gibt, werde ich mir das wohl nochmal angucken. Aber ich halte es einfach für unglaublich, daß Leute wirklich 150€ für MorphOS bezahlen - da ist ja wirklich überhaupt nichts ausgereift, wie es scheint.
Naja, wird das wohl nix mit libobjfw auf MorphOS porten. Wollte das ja mal auf ein eher unbekanntes System porten, MorphOS fliegt da wohl somit auch raus. AROS hat leider keinen ObjC-Support in ihrem GCC 4 und einen GCC 4 für AmigaOS konnte ich nicht finden (das CD-ROM Laufwerk tuts endlich wieder in meinem Amiga!). Unter QNX und Haiku fehlt ebenso der ObjC-Support in deren GCC 4 (wieso lassen den eigentlich alle raus? Er kostet sie rein GARNICHTS, sie kriegen ihn doch ohne irgendwelche Nachteile von GCC 4 gratis frei Haus! Einfach ein objc bei --enable-languages mit rein und fertig, ist das denn so schwer? Klar, ich könnte GCC 4 einfach selber neu bauen, aber das ist mir nur dafür dann auch wieder zu viel Aufwand, zumal das auf einigen garnicht so ohne weiteres ginge…).
Atom-Feed
Created: 01.01.2009 18:09 UTC
Das Blog gibt es ab sofort auch als Atom-Feed, und zwar hier. Vielen Dank hierbei an erlehmann für das Aufklären über die Probleme, die RSS hat. Der RSS-Feed wird daher auch in einer Woche entfernt, stellt also eure Reader schonmal auf den Atom-Feed um ;).
Frohes Neues!
Created: 31.12.2008 16:01 UTC
So, der Congress ist vorbei und somit auch ein weiteres Jahr. Aber noch ist es nicht Zeit, mal wieder zu schlafen, nein, erst ist da noch Silvester. Ja, obwohl ich seit 6 Tagen kaum Schlaf habe (2 - 3 Stunden pro Tag nur), wird heute abend natürlich gefeiert :). Somit wünsche ich euch allen schonmal ein frohes neues Jahr!
Was sind denn so eure Vorsätze? Ich denke, meiner wird sein, nichts mehr unverschlüsselt rauszusenden und einigen Legacy-Kram loszuwerden. Das wollt ich ja beides schon länger, aber der 25c3 hat mich darin nochmal bestärkt. Unverschlüsselt kann man echt nichts mehr machen (ich erwähne da nur das Beispiel, welches Tonnerre brachte, daß jemand sich unverschlüsselt eingeloggt hat und direkt wieder rausflog, weil jemand innerhalb von Sekunden schon sein Passwort geändert hatte). Und wie es mit Legacy-Kram aussieht, wurde ja auch mehrfach demonstriert :).
Naja, hoffen wir mal, daß 2009 nicht das Jahr der totalen Überwachung wird, auch wenn wir da scheinbar im Moment auf dem Weg hin sind.
Letzter 25c3-Tag
Created: 30.12.2008 19:43 UTC
Das wars, er ist vorbei, der 25c3. Ich sitze grade im Zug und kämpfe mal wieder mit der tollen GPRS-Verbindung (GPRS in Zügen scheint wohl generell so eine Sache zu sein - es sei denn, er steht grade. Telephonieren hingegen ist kein Problem; wird wohl an der anderen Modulation liegen), daher habe ich mich entschieden, stattdessen einen Blog-Eintrag zu machen - das kann man ja schließlich offline schreiben und später hochladen. Heute war ich gleich drei mal Video-Engel, einmal beim „La Quadrature du Net - Campaigning on Telecoms Package“-Talk, dann beim „Vertex Hacking“-Talk und schließelich auch bei der Closing Ceremony, die ich - wie auch so viele andere Schichten - für tec übernommen habe ;).
Mit dem Schlaf ist es mittlerweile echt extrem. Es wurde wirklich von Tag zu Tag weniger und gestern lag ich auch erst um 7 im Bett und um 11 mußte ich schon wieder raus. Wer konnte auch ahnen, daß ich zu Fuß schneller bin als die Straßenbahn? Am Tag davor bin ich zu Fuß gegangen und dachte, daß es mit der Straßenbahn dann ja erst recht vom Timing her keine Probleme gibt. Tja, falsch gedacht. Aber wer braucht schon Schlaf, wenn es Mate gibt? ;) Wobei das heute so ein Problem war. Mein Mate-Vorrat war leer und im Engel-Raum gab es auch nichts mehr. Nichtmal mehr Wasser. Dafür war der Kühlschrank aber voll mit Essen und Brötchen waren auch noch da.
Leider hab ichs jetzt nicht mehr geschafft, die Dumps der Streams zu ziehen, sodaß ich jetzt leider im Zug doch nicht die Talks gucken kann, die ich verpaßt habe. Im Moment weiß ich noch nicht, was ich bis morgen tun soll, da der ICE erst morgen fährt. Im bcc bleiben ist leider keine Option, das NOC hat schon alles abgebaut und somit bin ich dort genau so offline wie in Woltersdorf. Und nen ganzen Abend über GPRS online hängen, das wird teuer - denn ich kenne mich, wenn ich erstmal dran bin brauch ich nachher wieder irgendwelche Distfiles etc. und die über GPRS zu ziehen, das ist richtig teuer.
Alles in allem war es ein super Kongress. Die Netzanbindung war für die Größe des Kongresses sehr gut. Es gab natürlich hin und wieder ein paar Ausfälle etc., aber das ist bei der Größe auch nicht zu verhindern. Dafür, daß es 800 - 900 WLAN Nutzer gab, funktionierte das WLAN wirklich sehr gut (das Kabel-LAN war aber natürlich dennoch präferiert). Die Zahlen, die bei der Closing Ceremony präsentiert wurden, waren doch sehr beeindruckend. Interessant wäre natürlich gewesen, wenn man am Ende noch eine Statistik der Daten gemacht hätte, die man durch die GSM-BTS bekam. Im Talk wurde ja schon gezeigt, wie viel Prozent aus welchem Land kamen. Aber da noch ein paar Statistiken mehr wäre schon innteressant gewesen.
Insgesamt hat es mir sehr gut gefallen und ich werde wohl nächstes Jahr wieder dabei sein - vermutlich auch wieder als Video-Engel ;). Der Laptop mußte zwar einiges aushalten, physikalisch sowie auch in Sachen Software und Last, aber er hat alles gut überstanden :).
Der 3. Tag
Created: 30.12.2008 02:40 UTC
So, das war mal ein sehr anstrengender Tag, da eigentlich ständig irgedwas zu tun war und der Schlaf wie schon gesagt wirklich ein absolutes Minimum erreicht hatte. Ich wollte ja eigentlich ein bisschen CTF mitspielen, habe dann aber fast den ganzen CTF mit Engeleien verbracht. Das Team, wo ich zuerst war, hat sich auch irgendwie nicht organisiert gekriegt, sodaß ich dann nachher gewechselt hab. Als ich dann mit den Engeleien fertig und vom Essen zurück war, war der CTF auch schon gelaufen. Viel mehr als ein Advisory zu veröffentlichen und den Bug zu fixen hatte ich dann nicht gemacht.
Heute gab es nach dem „Privacy in the social semantic web“-Talk irgendwie das Bedürfnis, mal eine XMPP-Diskussionsrunde zu machen, was dann nachher in einer Diskussionsrunde beim Essen in einem Restaurant endete. Irgendwann hat man sich dann aufgelöst und wollte dann eigentlich einen Raum für morgen organisieren, aber leider war rein garnichts mehr frei.
Habe mir dann nachher noch Hacker Jeopardy angeguckt, war mal wieder recht unterhaltsam. Am besten mal das Video angucken, falls ihrs nicht gesehen habt.
Grade warte ich mal wieder auf den Zug. Bin zum ersten mal auf dem Congress müde, aber nach so wenig Schlaf ist das irgendwie langsam auch nur normal. Naja, morgen kann ich zumindest etwas länger schlafen. Mein 25c3-T-Shirt habe ich jetzt übrigens auch, allerdings noch garnicht anprobiert. Und ich glaube, irgendwie merkt man diesem Eintrag an, daß ich müde bin und grade versuche, die Zeit totzuschlagen.
GSM-(Un)Sicherheit
Created: 29.12.2008 11:48 UTC
So, ich war grade im „Running your own GSM network“-Talk als Video-Engel, nachdem ich heute wirklich auf den letzten Drücker ankam. Der Schlaf wird irgendwie von Tag zu Tag weniger. Gestern war es dann besonders extrem, da ich erst um 4:20 fahren konnte (blöderweise nicht nachgeguckt und somit nicht gesehen, daß nach 1 Uhr nichts mehr fährt und erst morgens um 4:20 wieder der 1. Zug fährt), ich dann bis Erkner gefahren bin und von da bis Woltersdorf, wo ich übernachte, zu Fuß laufen mußte und heute schon zum 1. Talk da sein mußte, weil ich da eben wie gesagt Video-Engel war. Der Talk jedenfalls war höchst interessant, auch wenn ich euch leider gegen Ende den Stream wegnehmen mußte ;). Ich habe dann oben selber auch weder Audio noch Video gehabt, sodaß ich mich dann auch noch in den Saal 1 gequetscht hatte - das wollte ich mir ja nicht entgehen lassen. Daß es um die Sicherheit von GSM sehr beunruhigend steht, das war ja eh klar. Aber wie extrem beunruhigend es ist, das wurde im Talk und in der Demonstration nochmal sehr deutlich. Ich kann wirklich jedem nur empfehlen, der es nicht gesehen hat, sich nachher das Video runterzuladen - dieses wird die Demonstration zwar auch nicht enthalten, aber der Talk ist drin - und der alleine lohnt sich auch.
Engel
Created: 28.12.2008 21:02 UTC
Da ist man grade zum 1. mal auf dem C3 und schon wird man am 2. Tag Engel :). Nachdem ich kurz für tec als Video-Engel eingesprungen bin, hab ich einen Engel-Ausweis bekommen. In der Mitte vom „Rapid Prototype Your Life“ habe ich dann also kurzzeitig die Übergänge übernommen ;). Allerdings gab es da am Anfang ein kleines technisches Problem, da der Sprecher eine Wide-Screen-Auflösung gewählt hatte, was dann kleine Kompatibilitätsprobleme mit dem Stream gab - falls ihr da also zwischendurch Rauschen gesehen habt oder euch gewundert habt, warum wir die Slides nicht gezeigt haben: Jetzt wisst ihrs, denn da mußte erst mal jemand hin und den Sprecher drauf aufmerksam machen. Danach ging es dann ins NOC, wo ich dann mal die gesamte Netzwerk-Hardware im Betrieb begutachten konnte - in tecs Blog gibts dann nachher Photos.
Nun also doch ein Blog…
Created: 28.12.2008 18:35 UTC
Also eigentlich war ich ja bisher immer gegen ein Blog. Ich mein, die Welt hat nun wirklich schon genug Blogs, warum sollte da ausgerechnet ich auch noch eins machen? Zumal viele ja nur des Hypes wegen sind und keinen wirklich Zweck erfüllen. Nun denn, nachdem ich jetzt aber in letzter Zeit des öfteren nach der URL zu meinem Blog gefragt wurde und jedesmal darauf nur damit antworten konnte, keines zu haben, wurde mir doch öfters nahegelegt, daß ein Blog vielleicht doch nicht ganz sinnlos wäre. Und wenn ich mal so eine Top-Liste der Fragen, die ich die letzten Tage in Jabber erhalten habe, erstellen würde, so sind dies alles Fragen, die man in einem Blog direkt vorwegnehmen könnte… Also denn, so habe nun auch ich ein Blog…
Da es aber scheinbar keine Blog-Software gibt, die nicht vollkommen evil ist, bloated ist oder einfach nur 5000 Dependencies hat, habe ich mir eben was kleines in Ruby geschrieben. Naja, eigentlich schreib ich hier einfach nur XHTML und das Ruby-Script macht dann noch nen RSS-Feed draus, indem es alle XHTML-Tags stripped. 2 Ruby-Files, mehr ist das nicht.
Ich hab sogar direkt was an Inhalt, sodaß der 1. Eintrag auch direkt einen Sinn hat :). Heute ist nämlich der 2. Tag des 25c3.
Die Hinfahrt war… nun gut, wie soll man sagen? Etwas holprig ;). Nachdem die Verspätung erst immer größer wurde, gab es dann schließlich auch noch eine Durchsage der Art „Sehr geehrte Fahrgäste, bitte verlassen Sie den Zug, das Triebwerk brennt“ - prima, noch mehr Verspätung! Naja, jedenfalls hab ich dann in letzter Minute noch nen weiterführenden Zug gefunden und bin dann total abgehetzt etc. nach 03:00 angekommen…
Mit viel zu wenig Schlaf hab ich mich dann am 1. Tag erstmal zur Keynote begeben, die mich jedoch ehrlich gesagt enttäuscht hat. Einigem konnte ich da einfach nicht zustimmen - und daß er die Bezeichnung „Nigger“ in seinem Talk verwandte, das fand ich dann echt nicht mehr angemessen. Die meiste Zeit des Tages habe ich dann einfach im Hackcenter verbracht, wo ich mich dann u.a. mal an einem Gajim-Patch für das Timeout-Problem probiert habe. Erste Versuche sehen recht erfolgversprechend aus. Im Moment habe ich die XMPP-Ping-Keepalives einfach deaktiviert und TCP/IP-Keepalives reingehackt - ein Aufruf von setsockopt, mehr ist das ja nicht. Unter Linux (daher konnte ich das nicht testen, ich habe nur ein PowerBook mit OS X drauf mit) kann man über 2 weitere Aufrufe von setsockopt sogar noch die Werte für die TCP/IP-Keepalives einstellen, sodaß der Patch das dort auch macht. Genügend Leute mit Linux für ein paar Tests sind hier ja vorhanden ;). Der 25c3 ist eigentlich auch ideal zum testen, da man hier abwechselnd ein stabiles LAN hat, wo man disconnected werden möchte, wenn der Gateway mal wieder weg ist, und WLAN, wo man nicht disconnected werden möchte, wenn es wieder einmal unerträglich laggt.
Das Netzwerk hier ist auch recht lustig. Der DHCP-Server hat plötzlich angefangen, mir Leases zu geben, die wer anders schon verwendet. Na gut, denkt man sich nicht viel bei und fordert eben ein neues. Aber als sich das ganze dann 5 mal wiederholte und es jedesmal ne andere IP war, die ich zugewiesen bekam und jedes mal eine andere MAC-Adresse war, die die wohl angeblich schon benutzt, hab ich mich dann doch mal ans NOC gewendet. Und als ich dann ein top auf dem DHCP-Server zu sehen bekam, wurd mir fast schlecht. Da liefen doch echt bestimmt 50 Prozesse mit dem Namen "perl5.8.8" als root, welche alle Resourcen des Rechners für sich beanspruchten. Als ich mal nachgefragt habe, hieß es, die seien wohl für die Firewall… Naja, mich würd das je beunruhigen. Perl - und dann auch noch als root? Und auch noch so viele davon? Aber ich glaube, ich will es eigentlich gar nicht wissen, was die da gemacht haben… Ein Durchgucken des Leases-File ergab jedenfalls, daß die IP meiner MAC zugewiesen war, dort aber auch ein 2. Eintrag ohne MAC und Hostname für die selbe IP war. Naja, irgendwann bin ich dann gegangen und es lief wieder. Ich vermute, daß entweder jemand ARP-Spoofing betrieben hat und sich für den DHCP-Server ausgegeben hat oder es eine Race Condition beim DHCP-Server gab. Bei der Last, die die Kiste hatte, wäre letzteres überhaupt nicht unwahrscheinlich.
Und dann wäre da noch die GSM-Basisstation. Jemand soll hier wohl 70 Stück haben und die für 140€ rausgeben, wenn man an der Software mithacken will. Klingt eigentlich ganz interessant, nur erscheinen mir die 140€ verflucht billig. Aber das wäre definitiv eine Alternative zu DECT-Phones. Wäre echt nett, wenn beim nächsten Congress ein Handy einfach wie ein DECT-Phone genutzt werden könnte :).
Heute ist wie gesagt der 2. Tag und ich hatte natürlich wieder viel zu wenig Schlaf, aber das war ja abzusehen. Talks habe ich mir heute noch keine angesehen, stattdessen saß ich eigentlich nur im Hackcenter. Viel gemacht habe ich eigentlich auch nicht, nur ein bisschen an libobjfw gehackt und eben dieses Blog geschrieben und angefangen zu füllen. Der Talk, für den ich extra früh aufgestanden bin, ist ja erst morgen - mein Verpeilfaktor halt. Aber der Tag ist ja noch lang ;).
So, für den 1. Blog-Eintrag ist das eigentlich schon wieder viel zu lang geraten. Wenn es was gibt, wofür ein Eintrag wirklich lohnt, dann wird es dafür wohl einen geben. Hauptsächlich werde ich hier wohl über Events und den aktuellen Status von Projekten, an denen ich hacke, bloggen. Denn das ist das, worüber ich am häufigsten in Jabber gefragt werde.
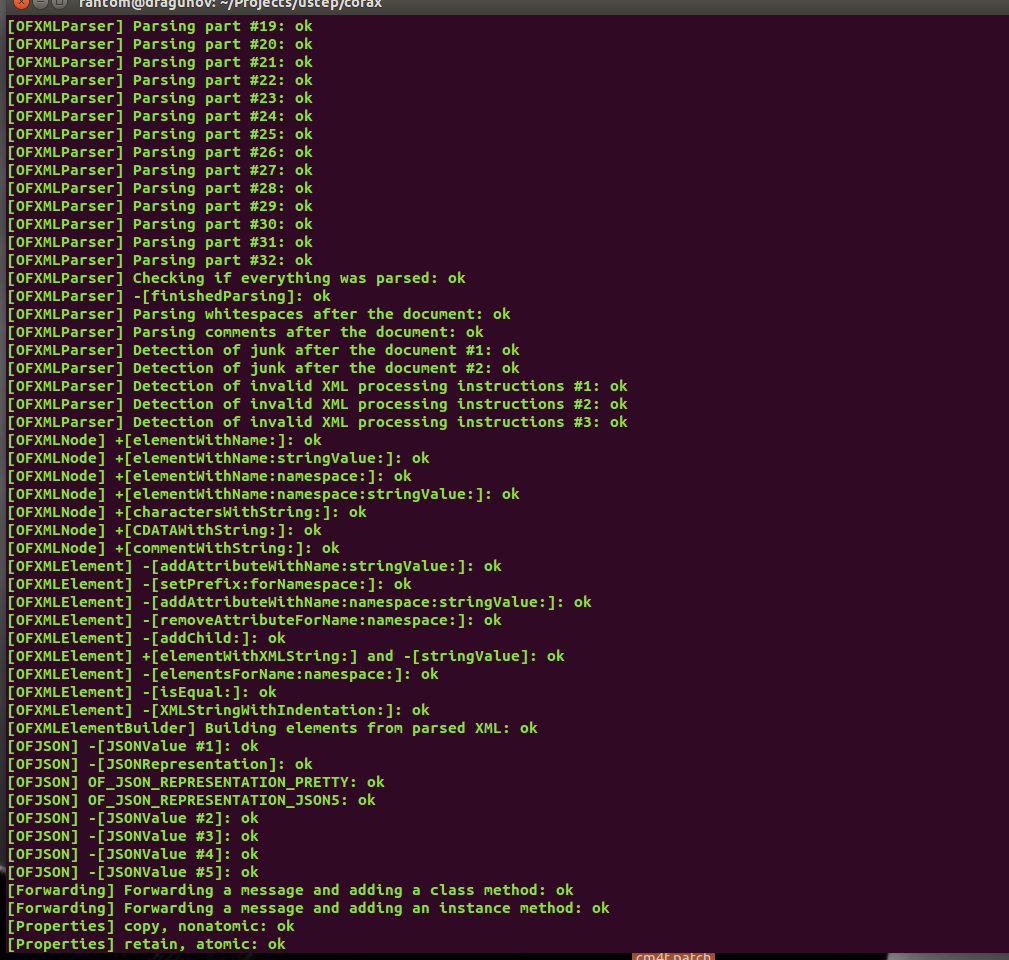{kind=link}
{kind=link}